Chapter 4 Ratings Paradigm
4.2 Introduction
In Chapter 2 the binary paradigm and associated concepts, primarily sensitivity and specificity, were introduced. Chapter 3 introduced the concepts of a random scalar decision variable, or z-sample, for each case, which is compared by the observer to a fixed reporting threshold \(\zeta\), resulting in two types of decisions - true and false positives. It described a statistical model characterized by two unit-variance normal distributions separated by \(\mu\), for the binary task. The concept of an underlying receiver operating characteristic (ROC) curve with the reporting threshold defining an operating point on the curve was introduced and the advisability of using the area under the curve as a measure of performance which is independent of reporting threshold was stressed.
In this chapter the more commonly used ratings method will be described which yields greater definition to the underlying ROC curve than just one operating point as obtained using the binary task, and moreover, it is more efficient.
In this method the observer assigns a rating (i.e., an ordered label) to each case. Described first is a typical ROC counts table and how operating points (i.e., pairs of FPF and TPF values) are obtained from the counts data. A labeling convention for the operating points is introduced. Notation is introduced for the observed integers in the counts table and the formulae for calculating operating points are presented. The ratings method is contrasted to the binary method in terms of efficiency and practicality. A theme occurring repeatedly in this book, that the ratings are not numerical values but rather they are ordered labels is illustrated with an example. A method of collecting ROC data on a 6-point scale is described that has the advantage of also yielding an unambiguous single operating point. The forced choice paradigm is described. Two controversies are described: one on the utility of discrete (e.g., 1 to 6) vs. quasi-continuous (e.g., 0 to 100) ratings and the other on the applicability of a clinical screening mammography-reporting scale for ROC analyses.
4.3 The ROC counts table
In a positive-directed rating scale with five discrete levels, the ratings could be the ordered labels:
- “1”: definitely non-diseased,
- “2”: probably non-diseased,
- “3”: could be non-diseased or diseased,
- “4”: probably diseased,
- “5”: definitely diseased.
At the conclusion of the ROC study an ROC counts table is constructed. This is the generalization to rating studies of the 2 x 2 table introduced in Table 2.1. 6
Table 4.1 is a representative counts table for a 5-rating study. It is the starting point for analysis. It lists the number of counts in each ratings bin, listed separately for non-diseased and diseased cases respectively. The data is from an actual clinical study (Barnes et al. 1989).
| \(r = 5\) | \(r = 4\) | \(r = 3\) | \(r = 2\) | \(r = 1\) | |
|---|---|---|---|---|---|
| non-diseased | 1 | 2 | 8 | 19 | 30 |
| diseased | 22 | 12 | 5 | 6 | 5 |
In this table: \(r = 5\) means “rating equal to 5”, \(r = 4\) means “rating equal to 4”, etc.
There are \(K_1 = 60\) non-diseased cases and \(K_2 = 50\) diseased cases. Of the 60 non-diseased cases:
- 1 received the “5” rating,
- 2 the “4” rating,
- eight the “3” rating,
- 19 the “2” rating and
- 30 the “1” rating.
The distribution of counts is tilted towards the “1” rating end. In contrast, the distribution of the diseased cases is tilted towards the “5” rating end. Of the 50 diseased cases:
- 22 received the “5” rating,
- 12 the “4” rating,
- 5 the “3” rating,
- 6 the “2” rating and
- 5 the “1” rating.
A little thought should convince the reader that the observed tilting of the counts is reasonable.
The spread of the counts appears to be more pronounced for the diseased cases, e.g., five of the 50 cases appeared to be definitely non-diseased to the observer. However, one is forewarned not to jump to conclusions about the spread of the data being larger for diseased than for non-diseased cases based on observed rating alone. While it turns out to be true the ratings are ordered labels, and further modeling is required, see Chapter 6, that uses only the ordering information implicit in the labels, not the actual values, to reach quantitative conclusions about the spread of each distribution.
4.4 Operating points from counts table
Table 4.2 illustrates how ROC operating points are calculated from the cell counts. In this table: \(r\geq 5\) means “counting ratings greater than or equal to 5”, \(r\geq 4\) means “counting ratings greater than or equal to 4”, etc.
| \(r\geq 5\) | \(r\geq 4\) | \(r\geq 3\) | \(r\geq 2\) | \(r\geq 1\) | |
|---|---|---|---|---|---|
| FPF | 0.0167 | 0.05 | 0.1833 | 0.5 | 1 |
| TPF | 0.4400 | 0.68 | 0.7800 | 0.9 | 1 |
One starts with non-diseased cases that were rated five or more (in this example, since 5 is the highest allowed rating, the “or more” clause is inconsequential) and divides by the total number of non-diseased cases, \(K_1 = 60\). This yields the abscissa of the lowest non-trivial operating point, namely \(\text{FPF}_{\ge5}\) = 1/60 = 0.017. The subscript on FPF is intended to make explicit which ratings are being cumulated. The corresponding ordinate is obtained by dividing the number of diseased cases rated “5” or more and dividing by the total number of diseased cases, \(K_2 = 50\), yielding \(\text{TPF}_{\ge5}\) = 22/50 = 0.440. Therefore, the coordinates of the lowest operating point are (0.017, 0.44). The abscissa of the next higher operating point is obtained by dividing the number of non-diseased cases that were rated “4” or more and dividing by the total number of non-diseased cases, i.e., \(\text{FPF}_{\ge4}\) = 3/60 = 0.05. Similarly the ordinate of this operating point is obtained by dividing the number of diseased cases that were rated “4” or more and dividing by the total number of diseased cases, i.e., \(\text{TPF}_{\ge4}\) = 34/50 = 0.680. The procedure, which at each stage cumulates the number of cases equal to or greater (in the sense of increased confidence level for disease presence) than a specified ordered label, is repeated to yield the rest of the operating points listed in Table 4.2. Since they are computed directly from the data without any assumptions they are called empirical operating points.
After doing this once, it would be nice to have a formula implementing the process, one use of which would be to code the procedure. But first one needs appropriate notation for the bin counts.
Let \(K_{1;r}\) denote the number of non-diseased cases rated \(r\), and \(K_{2;r}\) the number of diseased cases rated \(r\). Define dummy counts \(K_{1;R+1}\) = \(K_{2;R+1}\) = 0, where R is the number of ROC bins (and \(R = 5\) in the current example). This allows inclusion of the origin (0,0) in the formulae. The new range of \(r\) is defined as \(r = 1,2,...,(R+1)\). Within each truth-state, non-diseased or diseased, the individual bin counts sum to the total number of non-diseased and diseased cases, respectively. The following equations summarize these statements:
\[\begin{equation*} K_1=\sum_{r=1}^{R+1}K_{1;r} \end{equation*}\]
\[\begin{equation*} K_2=\sum_{r=1}^{R+1}K_{2;r} \end{equation*}\]
\[\begin{equation*} K_{1;R+1} = K_{2;R+1} = 0 \end{equation*}\]
\[\begin{equation*} r = 1,2,...,R+1 \end{equation*}\]
The operating points are defined by:
\[\begin{equation} \left. \begin{aligned} FPF_r=& \frac {1} {K_1} \sum_{s=r}^{R+1}K_{1;s}\\ TPF_r=& \frac {1} {K_2} \sum_{s=r}^{R+1}K_{2;s} \end{aligned} \right \} \tag{4.1} \end{equation}\]
4.4.1 Labeling the points
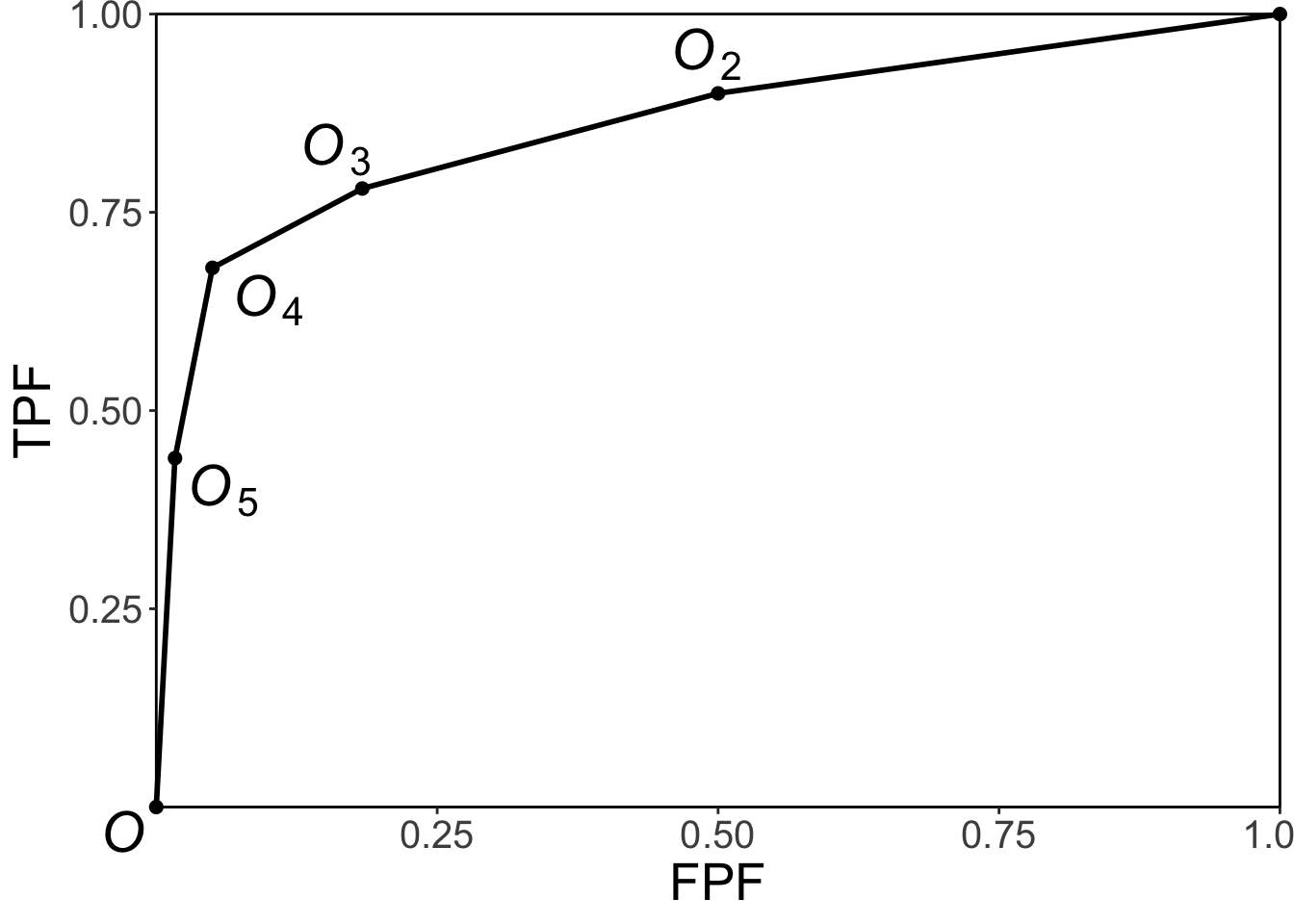
FIGURE 4.1: Operating point labeling convention and the empirical ROC plot.
The labeling \(O_n\) of the points follows the following convention, Fig. 4.1: from Eqn. (4.1) the point \(O_1\) corresponding to \(r=1\) would be the upper right corner (1,1) of the ROC plot, a trivial operating point since it is common to all datasets and is therefore not shown. The labeling starts with the next lower-left point, labeled \(O_2\), which corresponds to \(r=2\); the next lower-left point is labeled \(O_3\), corresponding to \(r=3\), etc., and the point labeled \(O_5\) is the lowest non-trivial operating point corresponding to \(r=5\) and finally \(O_{R+1}\) corresponding to \(r=R+1=6\) is the origin (0,0) of the ROC plot which is also a trivial operating point because it is common to all datasets and is therefore not shown.
To summarize, the operating points are labeled starting with the upper right corner, labeled \(O_2\), and working down the curve each time increasing the subscript by one. The maximum number of non-trivial points is \(R-1\).
4.4.2 Examples
In the following examples \(R = 5\) is the number of ROC bins and \(K_{1(R+1)}\) = \(K_{2(R+1)}\) = 0. If \(r = 1\) one gets the uppermost “trivial” operating point (1,1):
\[\begin{equation*} FPF_1=\frac {1} {K_1} \sum_{s=1}^{R+1}K_{1s} = \frac{60}{60} = 1\\ TPF_1=\frac {1} {K_2} \sum_{s=1}^{R+1}K_{2s} = \frac{50}{50} = 1 \end{equation*}\]
The uppermost non-trivial operating point is obtained for \(r = 2\), when:
\[\begin{equation*} FPF_2=\frac {1} {K_1} \sum_{s=2}^{R+1}K_{1s} = \frac{30}{60} = 0.5\\ TPF_2=\frac {1} {K_2} \sum_{s=2}^{R+1}K_{2s} = \frac{45}{50} = 0.9 \end{equation*}\]
The next lower operating point is obtained for \(r = 3\):
\[\begin{equation*} FPF_3=\frac {1} {K_1} \sum_{s=3}^{R+1}K_{1s} = \frac{11}{60} = 0.183\\ TPF_3=\frac {1} {K_2} \sum_{s=3}^{R+1}K_{2s} = \frac{39}{50} = 0.780 \end{equation*}\]
The next lower operating point is obtained for \(r = 4\):
\[\begin{equation*} FPF_4=\frac {1} {K_1} \sum_{s=4}^{R+1}K_{1s} = \frac{3}{60} = 0.05\\ TPF_4=\frac {1} {K_2} \sum_{s=4}^{R+1}K_{2s} = \frac{34}{50} = 0.680 \end{equation*}\]
The lowest non-trivial operating point is obtained for \(r = 5\):
\[\begin{equation*} FPF_5=\frac {1} {K_1} \sum_{s=5}^{R+1}K_{1s} = \frac{1}{60} = 0.017\\ TPF_5=\frac {1} {K_2} \sum_{s=5}^{R+1}K_{2s} = \frac{22}{50} = 0.440 \end{equation*}\]
The next value \(r = 6\) yields the trivial operating point (0,0):
\[\begin{equation*} FPF_6=\frac {1} {K_1} \sum_{s=6}^{R+1}K_{1s} = \frac{0}{60} = 0\\ TPF_6=\frac {1} {K_2} \sum_{s=6}^{R+1}K_{2s} = \frac{0}{50} = 0 \end{equation*}\]
This exercise shows explicitly that an R-rating ROC study can yield, at most, \(R + 1\) distinct non-trivial operating points; i.e., those corresponding to \(r=2,3,...,R\).
The modifier “at most” is needed, because if both counts (i.e., non-diseased and diseased) for bin \(r'\) are zeroes, then that operating point merges with the one immediately below-left of it:
\[\begin{equation*} FPF_{r'}=\frac {1} {K_1} \sum_{s={r'}}^{R+1}K_{1s} = \frac {1} {K_1} \sum_{s={r'+1}}^{R+1}K_{1s} = FPF_{r'+1}\\ \\ TPF_{r'}=\frac {1} {K_2} \sum_{s={r'}}^{R+1}K_{2s} = \frac {1} {K_2} \sum_{s={r'+1}}^{R+1}K_{2s} = TPF_{r'+1} \end{equation*}\]
Since bin \(r'\) is unpopulated, one can re-label the bins to exclude the unpopulated bin, and now the total number of bins is effectively \(R-1\).
Since one is cumulating counts, which cannot be negative, the highest non-trivial operating point resulting from cumulating the 2 through 5 ratings has to be to the upper-right of the next adjacent operating point resulting from cumulating the 3 through 5 ratings. This in turn has to be to the upper-right of the operating point resulting from cumulating the 4 through 5 ratings and finally this has to be to the upper right of the operating point resulting from the 5 ratings. In other words, as one cumulates ratings bins, the operating point must move monotonically up and to the right, or more accurately, the point cannot move down or to the left. If a particular bin has zero counts for non-diseased cases, and non-zero counts for diseased cases, the operating point moves vertically up when this bin is cumulated; if it has zero counts for diseased cases, and non-zero counts for non-diseased cases, the operating point moves horizontally to the right when this bin is cumulated.
4.5 Implemention in code
It is useful to replace the preceding detailed explanation with a simple algorithm, as in the following code (lines 1 - 5):
options(digits = 3)
FPF <- OpPts[1,]
TPF <- OpPts[2,]
df <- data.frame(FPF = FPF, TPF = TPF)
df <- t(df)
print(df)
#> [,1] [,2] [,3] [,4] [,5]
#> FPF 0.0167 0.05 0.183 0.5 1
#> TPF 0.4400 0.68 0.780 0.9 1
# ev = equal variance model
mu_ev <- qnorm(.5)+qnorm(.9);sigma_ev <- 1
Az_ev <- pnorm(mu_ev/sqrt(2))
cat("uppermost point based estimate of mu_ev = ", mu_ev, "\n")
#> uppermost point based estimate of mu_ev = 1.28
cat("corresponding estimate of Az_ev = ", Az_ev, "\n")
#> corresponding estimate of Az_ev = 0.818Notice that the values of the arrays FPF and TPF are identical to those listed in Table 4.2. Regarding lines 10 and 11 of code it was shown in Chapter 2 that in the equal variance binormal model the operating point determines the parameters \(\mu_{ev}\) = 1.282, Eqn. (3.17), or equivalently \(A_{z;\sigma = 1}\) = 0.818, Eqn. (3.23). These lines illustrate the application of these formulae using the coordinates (0.5, 0.9) of the uppermost non-trivial operating point, i.e., one is fitting the equal variance model to the uppermost operating point.
Shown next is the equal-variance model fit to the uppermost non-trivial operating point, left panel, and for comparison, the right panel is the unequal variance model fit to all operating points (the unequal variance model is described in the next chapter).
# equal variance fit to uppermost operating point
p1 <- plotROC (mu_ev, sigma_ev, FPF, TPF)
# the following values are from unequal-variance model fitting
# to be discussed in the next chapter
mu <- 2.17;sigma <- 1.65
# following formula is discussed in the next chapter
Az <- pnorm(mu/sqrt(1+sigma^2))
cat("binormal unequal variance model estimate of Az = ", Az, "\n")
#> binormal unequal variance model estimate of Az = 0.87
# unequal variance fit to all operating points
p2 <- plotROC (mu, sigma, FPF, TPF)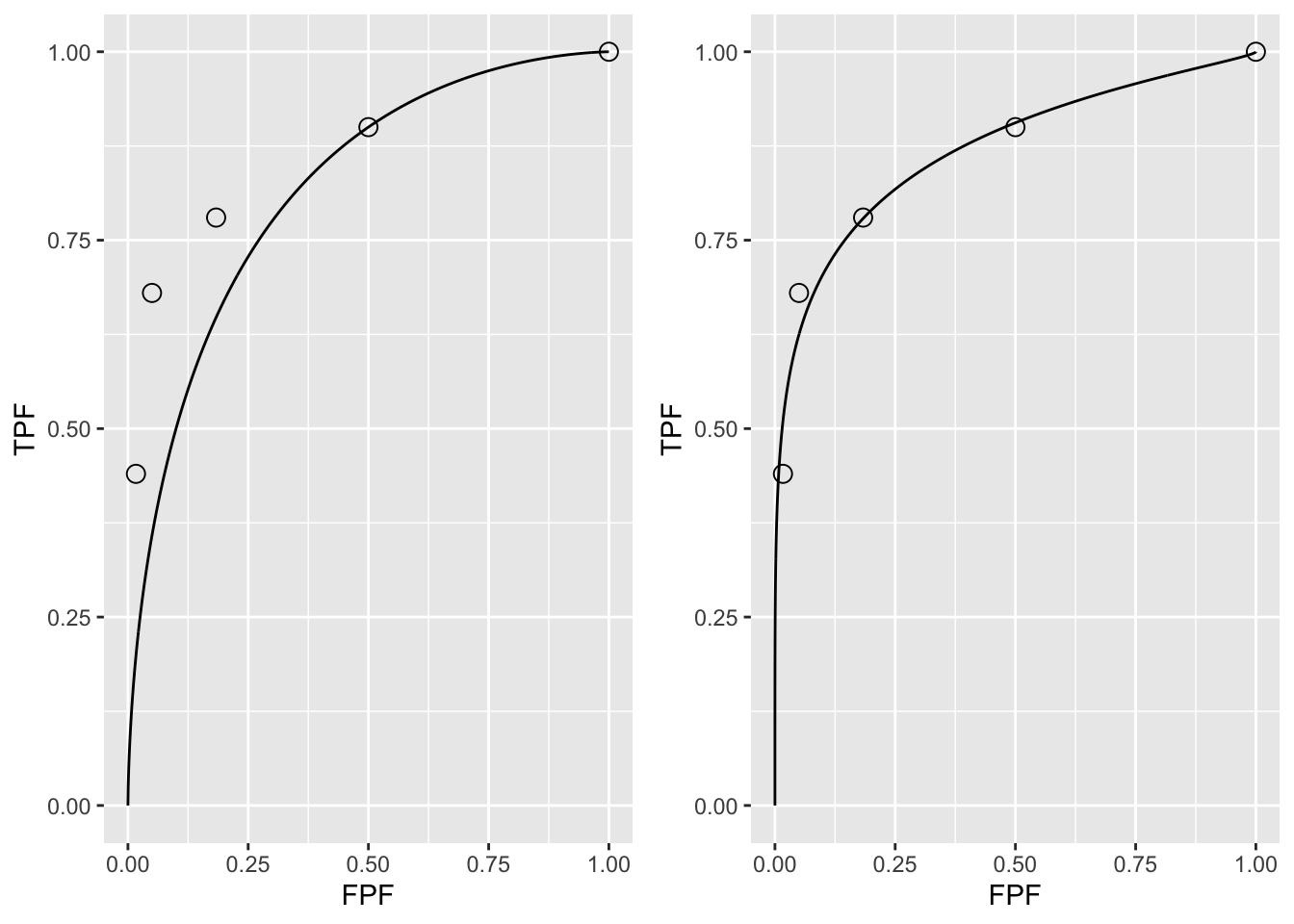
FIGURE 4.2: A: This panel is the predicted ROC curve for \(\mu=1.28\) superposed on the operating points. B: This panel is the same data fitted with a unequal variance model described in a following chapter.
It should come as no surprise that the uppermost operating point in panel A is exactly on the predicted curve: after all, this point was used to calculate \(\mu_{ev}\) = 1.282. The corresponding value of \(\zeta\) can be calculated from Eqn. (3.15), namely:
\[\begin{equation*} \zeta = \Phi^{-1}\left ( Sp \right ) \tag{4.2} \end{equation*}\]
\[\begin{equation*} \mu = \zeta + \Phi^{-1}\left ( Se \right ) \tag{4.3} \end{equation*}\]
These are coded below:
# Sp = 1 - FPF = 1 - 0.5
# Se = 0.9
cat("zeta from Sp = ", qnorm(1-0.5),"\n")
#> zeta from Sp = 0
cat("zeta from Se = ", mu_ev-qnorm(0.9),"\n")
#> zeta from Se = 0Either way, one gets the same result: \(\zeta\) = 0. This should make sense as FPF = 0.5 is consistent with half of the (symmetrical) unit-normal non-diseased distribution being above \(\zeta\) = 0.
Exercise: calculate \(\zeta\) for each of the remaining operating points. Notice that \(\zeta\) increases as one moves down the curve.
In Fig. 4.2 panel A show that the ROC curve, as determined by the uppermost operating point, passes exactly through this point but misses the others. If a different operating point were used to estimate \(\mu_{ev}\) and \(A_{z;\sigma = 1}\) the values would have been different and the new curve would pass exactly through the new selected point. No single-point based choice of \(\mu{ev}\) would yield a satisfactory visual fit to all the observed operating points. This is the reason one needs a modified model, namely the unequal variance binormal model, to fit radiologist data.
Fig. 4.2 panel B shows the predicted ROC curve by the unequal variance binormal model, to be introduced in a following chapter. The corresponding parameter values are \(\mu\) = 2.17 and \(\sigma\) = 1.65.
Notice the improved visual quality of the fit, especially if one keeps in mind that each observed point is subject to sampling variability, see Eqn. (3.32) and Eqn. (3.34). 7
4.6 Relation between ratings paradigm and the binary paradigm
Table 4.1 and Table 4.2 correspond to \(R = 5\). In Chapter 2 it was shown that the binary task requires a single fixed threshold parameter \(\zeta\) and a binning rule Eqn. (4.4): if \(z > \zeta\) assign a rating of 2 and otherwise assign a rating of 1.
The R-rating task can be viewed as \(R-1\) simultaneously conducted binary tasks each with its own fixed threshold \(\zeta_r\), where r = 1, 2, …, R-1. It is efficient compared to \(R-1\) sequentially conducted binary tasks; however, the onus is on the observer to maintain fixed-multiple thresholds through the duration of the study.
The rating method is a more efficient way of collecting the data compared to running the study repeatedly with appropriate instructions to cause the observer to adopt different fixed thresholds. In the clinical context such repeated studies would be impractical because it would introduce memory effects wherein the diagnosis of a case would depend on how many times the case had been seen in previous sessions.
In order to model the binning, one defines dummy thresholds \(\zeta_0 = - \infty\) and \(\zeta_R = + \infty\), in which case the thresholds satisfy the ordering requirement \(\zeta_{r-1} \le \zeta_r\) , r = 1, 2, …, R. The rating or binning rule is:
\[\begin{equation} \left. \begin{aligned} \text{if} \left (\zeta_{r-1} \le z < \zeta_r \right )&\Rightarrow \text{rating} = r\\ &r = 1, 2, ..., R \end{aligned} \right \} \tag{4.4} \end{equation}\]
For Table 4.2, the empirical thresholds are as follows:
\[\begin{equation} \left. \begin{aligned} \zeta_r &= r + 1 \\ r &= 0, 1, ..., R-1\\ \zeta_0 &= -\infty\\ \zeta_R &= \infty\\ \end{aligned} \right \} \tag{4.5} \end{equation}\]
The empirical thresholds are integers, not floating point values predicted by Eqn. (4.2). Either way one gets the same operating points. This is a subtle and important distinction explained further in the next section.
In Table 4.1 the number of bins is \(R = 5\). The “simultaneously conducted binary tasks” nature of the rating task can be appreciated from the following examples. Suppose one selects the threshold for the first binary task to be \(\zeta_4 = 5\). By definition, \(\zeta_5 = \infty\); therefore a case rated 5 satisfies the binning rule \(\zeta_4 \leq 5 < \zeta_5\), i.e., Eqn. (4.4). The operating point corresponding to \(\zeta_4 = 5\), obtained by cumulating all cases rated five, yields \((0.017, 0.440)\). In the second binary-task, one selects as threshold \(\zeta_3 = 4\). Therefore, a case rated four satisfies the binning rule \(\zeta_3 \leq 4 < \zeta_4\). The operating point corresponding to \(\zeta_3 = 4\), obtained by cumulating all cases rated four or five, yields \((0.05, 0.680)\). Similarly, for \(\zeta_2 = 3\), \(\zeta_1 = 2\) and \(\zeta_0 = -\infty\), which cumulates counts in bins 3, 2 and 1, respectively. The 1-bin yields a trivial operating point (1,1). The non-trivial operating points are generated by thresholds \(\zeta_r\), where \(r\) = 1, 2, 3 and 4. A five-rating study has four associated thresholds and a corresponding number of equivalent binary studies.
4.7 Ratings are not numerical values
The ratings are to be thought of as ordered labels, not as numeric values. Arithmetic operations that are allowed on numeric values, such as averaging, are not allowed on ratings. One could have relabeled the ratings in Table 4.2 as A, B, C, D and E, where A < B etc. As long as the counts in the body of the table are unaltered, such relabeling would have no effect on the observed operating points and the fitted curve. Of course one cannot average the labels A, B, etc. of different cases. The issue with numeric labels is not fundamentally different. At the root is that the difference in thresholds corresponding to the different operating points are not in relation to the difference between their numeric values. There is a way to estimate the underlying thresholds, if one assumes a specific model, for example the unequal-variance binormal model to be described in Chapter 06. The thresholds so obtained are genuine numeric values and can be averaged. [Not to hold the reader in suspense, the four thresholds corresponding to the data in Table 4.1 are 0.007676989, 0.8962713, 1.515645 and 2.396711; see §6.4.1; these values would be unchanged if, for example, the labels were doubled, with allowed values 2, 4, 6, 8 and 10, or any of an infinite number of rearrangements that preserves their ordering.]
The temptation to regard confidence levels / ratings as numeric values can be particularly strong when one uses a large number of bins to collect the data. One could use of quasi-continuous ratings scale, implemented for example, by having a slider-bar user interface for selecting the rating. The slider bar typically extends from 0 to 100, and the rating could be recorded as a floating-point number, e.g., 63.45. Here too one cannot assume that the difference between a zero-rated case and a 10 rated case is a tenth of the difference between a zero-rated case and a 100 rated case. So averaging the ratings is not allowed. Additionally, one cannot assume that different observers use the labels in the same way. One observer’s 4-rating is not equivalent to another observers 4-rating.
Working directly with the ratings is a very bad idea: valid analytical methods use the rankings of the ratings, not their actual values. The reason for the emphasis is that there are serious misconceptions about ratings. I am aware of a publication stating, to the effect, that a modality resulted in an increased average confidence level for diseased cases. Another publication used a specific numerical value of a rating to calculate the operating point for each observer – this assumes all observers use the rating scale in the same way, which they do not.
4.8 A single “clinical” operating point from ratings data
The reason for the quotes in the title to this section is that a single operating point on a laboratory ROC plot, no matter how obtained, has little relevance to how radiologists operate in the clinic. However, some consider it useful to quote an operating point from an ROC study. For a 5-rating ROC study, Table 4.1, it is not possible to unambiguously calculate the operating point of the observer in the binary task of discriminating between non-diseased and diseased cases. One possibility would be to use the “three and above” ratings to define the operating point, but one might jus have well have chosen “two and above”. A second possibility is to instruct the radiologist that a “four and above” rating, for example, implies the case would be reported “clinically” as diseased. However, the radiologist can only pretend so far that this study, which has no clinical consequences, is somehow a “clinical” study.
If a single laboratory study based operating point is desired (Nishikawa 2012), the best strategy, in my opinion, is to obtain the rating via two questions. This method is also illustrated in Table 3.1 of a book on detection theory (Macmillan and Creelman 2004). The first question is “is the case diseased?” The binary (Yes/No) response to this question allows unambiguous calculation of the operating point. The second question is: “what is your confidence in your previous decision?” and allow three responses, namely Low, Medium and High. The dual-question approach is equivalent to a 6-point rating scale, Fig. 4.3. The answer to the first question, is the patient diseased, allows unambiguous construction of a single “clinical” operating point for disease presence. The answer to the second question yields multiple operating points.
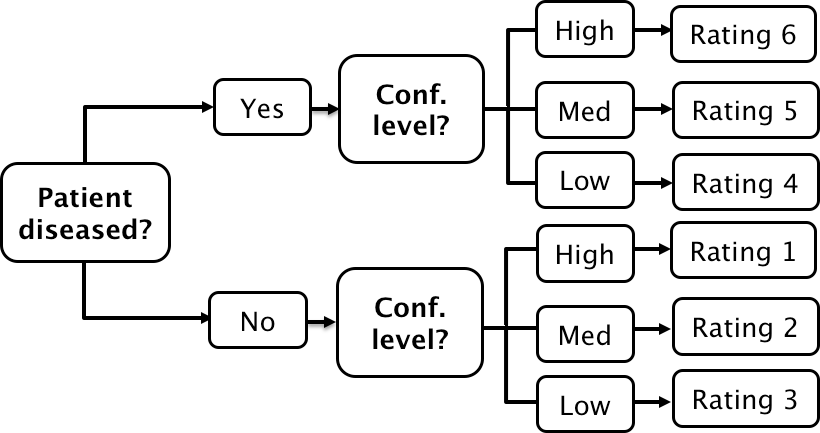
FIGURE 4.3: A method for acquiring ROC data on an effectively 6-point scale that also yields an unambiguous single operating point for declaring patients diseased. Note the reversal of the ordering of the final ratings in the last “column” in the lower half of the figure.
The ordering of the ratings can be understood as follows. The four, five and six ratings are as expected. If the radiologist states the patient is diseased and the confidence level is high that is clearly the highest end of the scale, i.e., six, and the lower confidence levels, five and four, follow, as shown. If, on the other hand, the radiologist states the patient is non-diseased, and the confidence level is high, then that must be the lowest end of the scale, i.e., “1”. The lower confidence levels in a negative decision must be higher than “1”, namely “2” and “3”, as shown. As expected, the low confidence ratings, namely “3” (non-diseased, low confidence) and “4” (diseased, low confidence) are adjacent to each other. With this method of data-collection, there is no confusion as to what rating defines the single desired operating point as this is determined by the binary response to the first question. The 6-point rating scale is also sufficiently fine to not smooth out the ability of the radiologist to maintain distinct different levels. In my experience, using this scale one expects rating noise of about \(\pm\frac{1}{2}\) a rating bin, i.e., the same difficult case, shown on different occasions to the same radiologist (with sufficient time lapse or other intervening cases to minimize memory effects) is expected to elicit a “3” or “4”, with roughly equal probability.
4.9 The forced choice paradigm
In each of the four paradigms (ROC, FROC, LROC and ROI) described in Chapter 1.2, patient images are displayed one patient at a time. A fifth paradigm involves presentation of multiple images simultaneously to the observer, where one image is from a diseased patient, and the rest are from non-diseased patients. The observer’s task is to pick the image that is most likely to be from the diseased patient. If the observer is correct, the event is scored as a “one” and otherwise it is scored as a “zero”. The process is repeated with other sets of independent patient images, each time satisfying the condition that one patient is diseased and the rest are non-diseased. The sum of the scores divided by the total number of scores is the probability of a correct choice, denoted \(P(C)\). If the total number of cases presented at the same time is denoted \(n\), then the task is termed n-alternative forced choice or nAFC (Green, Swets, et al. 1966). If only two cases are presented, one diseased and the other non-diseased, then n = 2 and the task is 2AFC. In Fig. 4.4, in the left image a Gaussian nodule is superposed on a square region extracted from a non-diseased mammogram. The right image is a region extracted from a different non-diseased mammogram (one should not use the same background in the two images – the analysis assumes that different, i.e., independent images, are shown). If the observer clicks on the left image, a correct choice is recorded. [In some 2AFC-studies, the backgrounds are simulated non-diseased images. They resemble mammograms; the resemblance depends on the expertise of the observer: expert radiologists can tell that they are not true mammograms. They are actually created by filtering the random white noise with a \(1/f^3\) spatial filter (Burgess 2011).]
The 2AFC paradigm is popular because its analysis is straightforward and there is a theorem (Green, Swets, et al. 1966) that \(P(C)\), the probability of a correct choice in the 2AFC task equals the area under the true (not fitted, not empirical) ROC curve. Another reason for its popularity is possibly the speed at which data can be collected, sometimes only limited by the speed at which disk stored images can be displayed on the monitor. While useful for studies into human visual perception on relatively simple images, and the model observer community has performed many studies using this paradigm, I cannot recommend it for clinical studies because it does not resemble any clinical task. Additionally, the forced-choice paradigm is wasteful of known-truth images, often a difficult/expensive resource to come by, because narrower confidence intervals are obtained using the ratings ROC method or by utilizing location specific extensions of the ROC paradigm.

FIGURE 4.4: Example of image presentation in a 2AFC study.
Fig. 4.4: Example of image presentation in a 2AFC study. The left image contains, at its center, a positive contrast Gaussian shape disk superposed on a non-diseased mammogram. The right image does not contain a lesion at its center and the background is from a different non-diseased patient. If the observer clicks on the left image it is recorded as a correct choice, otherwise it is recorded as an incorrect choice. The number of correct choices divided by the number of paired presentations is an estimate of the probability of a correct choice, which can be shown to be identical to the true area under the ROC curve.
4.10 Observer performance studies as laboratory simulations of clinical tasks
Observer performance paradigms (ROC, FROC, LROC and ROI) should be regarded as experiments conducted in a laboratory (i.e., controlled) setting that are intended to be representative of the actual clinical task. They should not to be confused with performance in a real “live” clinical setting: there is a known “laboratory effect” (Gur et al. 2008). For example, in the just cited study radiologists performed better during live clinical interpretations than they did later, on the same cases, in a laboratory ROC study. This is to be expected because there is more at stake during live interpretations: e.g., the patient’s health and the radiologist’s reputation, than during laboratory ROC studies.
Real clinical interpretations happen every day in radiology departments all over the world. On the other hand, in the laboratory, the radiologist is asked to interpret the images “as if in a clinical setting” and render a “diagnosis”. The laboratory decisions have no clinical consequences. Usually laboratory ROC studies are conducted on retrospectively acquired images. Patients, whose images are used in an ROC study, have already been imaged in the clinic and decisions have already been made on how to manage them.
There is no guarantee that results of the laboratory study are directly applicable to clinical practice. Indeed there is an assumption that the laboratory study correlates with clinical performance. The correlation is taken to be an axiomatic truth by researchers when, in fact, it is an assumption.
This section should not be interpreted as expressing my lack of trust in laboratory studies. Simulations are widely used in “hard” sciences, e.g., they are used in astrophysics to determine conditions dating to \(10^{-31}\) seconds after the big bang. Conducting clinical studies is very difficult as there are many factors not under the researcher’s control. Observer performance studies of the type described in this book are the closest that one can come to the “real thing” as they include key elements of the actual clinical task: the entire imaging system, radiologists (assuming the radiologists’ brings their full expertise to bear on each image interpretation) and real clinical images.
4.11 Discrete vs. continuous ratings: the Miller study
There is controversy about the merits of discrete vs. continuous ratings (Rockette, Gur, and Metz 1992; Wagner, Beiden, and Metz 2001). The late Prof. Charles E. Metz and the late Dr. Robert F. Wagner have both backed the latter (i.e., continuous or quasi-continuous ratings) and new ROC study designs sometimes tend to follow their advice. I recommend a 6-point rating scale as outlined in Fig. 4.3. This section provides the background for the recommendation.
A widely cited (39,704 citations at the time of writing, ca. March 2023) paper by Miller (Miller 1956) titled “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information” is relevant. It is a readable paper, freely downloadable in several languages (www.musanim.com/miller1956/). In my judgment, this paper has not received the attention it should have in the ROC community, and for this reason portions from it are reproduced below. [George Armitage Miller, February 3, 1920 – July 22, 2012, was one of the founders of the field of cognitive psychology.]
Miller’s first objective was to comment on absolute judgments of unidimensional stimuli. Since all (univariate, i.e., single decision per case) ROC models assume a unidimensional decision variable, Miller’s work is highly relevant. He comments on two papers by Pollack (Pollack 1952, 1953). Pollack asked listeners to identify tones by assigning numerals to them, analogous to a rating task described above. The tones differed in frequency, covering the range 100 to 8000 Hz in equal logarithmic steps. A tone was sounded and the listener responded by giving a numeral (i.e., a rating, with higher values corresponding to higher frequencies). After the listener had made his response, he was told the correct identification of the tone. When only two or three tones were used, the listeners never confused them. With four different tones, confusions were quite rare, but with five or more tones, confusions were frequent. With fourteen different tones, the listeners made many mistakes. Since it is so succinct, the entire content of the first (1952) paper by Pollack is reproduced below:
“In contrast to the extremely acute sensitivity of a human listener to discriminate small differences in the frequency or intensity between two sounds is his relative inability to identify (and name) sounds presented individually. When the frequency of a single tone is varied in equal‐logarithmic steps in the range between 100 cps and 8000 cps (and when the level of the tone is randomly adjusted to reduce loudness cues), the amount of information transferred is about 2.3 bits per stimulus presentation. This is equivalent to perfect identification among only 5 tones. The information transferred, under the conditions of measurement employed, is reasonably invariant under wide variations in stimulus conditions.”
By “information” is meant the number of levels, measured in bits (binary digits), thereby making it independent of the unit of measurement: 1 bit corresponds to a binary rating scale, 2 bits to a four-point rating scale and 2.3 bits to \(2^{2.3}\) = 4.9, i.e., about 5 ratings bins. Based on Pollack’s’ original unpublished data, Miller put an upper limit of 2.5 bits (corresponding to about 6 ratings bins) on the amount of information that is transmitted by listeners who make absolute judgments of auditory pitch. The second paper (@ Pollack 1953) by Pollack was related to: (1) the frequency range of tones; (2) the utilization of objective reference tones presented with the unknown tone; and (3) the “dimensionality”—the number of independently varying stimulus aspects. Little additional gain in information transmission was associated with the first factor; a moderate gain was associated with the second; and a relatively substantial gain was associated with the third (we return to the dimensionality issue below).
As an interesting side-note, Miller states:
“Most people are surprised that the number is as small as six. Of course, there is evidence that a musically sophisticated person with absolute pitch can identify accurately any one of 50 or 60 different pitches. Fortunately, I do not have time to discuss these remarkable exceptions. I say it is fortunate because I do not know how to explain their superior performance. So I shall stick to the more pedestrian fact that most of us can identify about one out of only five or six pitches before we begin to get confused.”
“It is interesting to consider that psychologists have been using seven-point rating scales for a long time on the intuitive basis that trying to rate into finer categories does not really add much to the usefulness of the ratings. Pollack’s results indicate that, at least for pitches, this intuition is fairly sound.”
“Next you can ask how reproducible this result is. Does it depend on the spacing of the tones or the various conditions of judgment? Pollack varied these conditions in a number of ways. The range of frequencies can be changed by a factor of about 20 without changing the amount of information transmitted more than a small percentage. Different groupings of the pitches decreased the transmission, but the loss was small. For example, if you can discriminate five high-pitched tones in one series and five low-pitched tones in another series, it is reasonable to expect that you could combine all ten into a single series and still tell them all apart without error. When you try it, however, it does not work. The channel capacity for pitch seems to be about six and that is the best you can do.”
DPC comment: I was unable to find a single study in the medical imaging field of the number of discrete rating levels that an observer can support.
There is no question that for multidimensional data, as observed in the second study by Pollack (Pollack 1953), the observer can support more than 7 ratings bins. To quote Miller:
“You may have noticed that I have been careful to say that this magical number seven applies to one-dimensional judgments. Everyday experience teaches us that we can identify accurately any one of several hundred faces, any one of several thousand words, any one of several thousand objects, etc. The story certainly would not be complete if we stopped at this point. We must have some understanding of why the one-dimensional variables we judge in the laboratory give results so far out of line with what we do constantly in our behavior outside the laboratory. A possible explanation lies in the number of independently variable attributes of the stimuli that are being judged. Objects, faces, words, and the like differ from one another in many ways, whereas the simple stimuli we have considered thus far differ from one another in only one respect.”
DPC comment: In the medical imaging context, a trivial way to increase the number of ratings would be to color-code the images: e.g., red, green and blue; now one can assign a red image rated 3, a green image rated 2, etc., which would be meaningless unless the colors encode relevant diagnostic information. Another ability, quoted in the publication (Wagner, Beiden, and Metz 2001) advocating continuous ratings is the ability to recognize faces, again a multidimensional categorization task, addressed by Miller (see above). Also quoted as an argument for continuous ratings is the ability of computer aided detection schemes that calculate many features for each perceived lesion and combine them into a single probability of malignancy, which is on a highly precise floating point 0 to 1 scale. Radiologists are not computers. Other arguments for greater number of bins: it cannot hurt and one should acquire the rating data at greater precision than the noise, especially if the radiologist is able to maintain the finer distinctions. I worry that radiologists who are willing to go along with greater precision are over-anxious to co-operate with the study designer. Expert radiologists will not modify their reading style and one should be suspicious when they do accede to an investigators request to interpret images in a style that does not resemble the clinic. Radiologists, especially experts, do not like more than about four ratings. I once worked closely with a famous chest radiologist (the late Dr. Robert Fraser) who refused to use more than four ratings. 8
Another reason given for using continuous ratings is it reduces instances of data degeneracy. Data is sometimes said to be degenerate if the curve-fitting algorithm cannot fit it (in simple terms, the program “crashes” or reports unphysical parameter values). This occurs if there are no interior points on the ROC plot. Modifying radiologist behavior to accommodate the limitations of analytical methods seems to be inherently dubious. One could simply randomly add or subtract half an integer from the observed ratings thereby making the rating scale more granular and thus reduce instances of degeneracy (this is actually done in some ROC software to overcome this problem). Another possibility is to use the empirical (trapezoidal) area under the ROC curve, which can always be calculated. Actually, fitting methods now exist that are robust to data degeneracy, such as discussed in Chapter 7 and in the RSM fitting chapter in TBA
RJafrocFrocBook, so this reason for acquiring continuous data is no longer valid.The rating task involves a unidimensional scale and I see no way of getting around the basic channel-limitation noted by Miller and for this reason I recommend a 6 point scale, as in Fig. 4.3.
On the other side of the controversy (Berbaum et al. 2002), a position that I agree with, it has been argued that given a large number of allowed ratings levels the cooperating observer essentially bins the data into a much smaller number of bins (e.g., 0, 20, 40, 60, 80, 100) and then adds a zero-mean noise term to appear to be “spreading out the ratings”. This ensures that the binormal model does not “crash”. However, if the intent is to get the observer to spread the ratings, so that the binormal model does not “crash”, a better approach is to use alternate models that do not “crash” and are, in fact, very robust with respect to degeneracy of the data.
4.12 The BI-RADS ratings scale and ROC studies
It is desirable that the rating scale be relevant to the radiologists’ daily practice. This assures greater consistency – the fitting algorithms assume that the thresholds are held constant for the duration of the ROC study. Depending on the clinical task, a natural rating scale may already exist. For example, the American College of Radiology has developed the Breast Imaging Reporting and Data System (BI-RADS) to standardize mammography reporting (Liberman and Menell 2002). There are six assessment categories: category 0 indicates need for additional imaging; category 1 is a negative (clearly non-diseased); category 2 is a benign finding; category 3 is probably benign, with short-interval follow-up suggested; category 4 is a suspicious abnormality for which biopsy should be considered; category 5 is highly suggestive of malignancy and appropriate action should be taken. The 4th edition of the BI-RADS manual divides category 4 into three subcategories 4A, 4B and 4C and adds category 6 for a proven malignancy. The 3-category may be further subdivided into “probably benign with a recommendation for normal or short-term follow-up” and a 3+ category, “probably benign with a recommendation for immediate follow-up”. Apart from categories 0 and 2, the categories form an ordered set with higher categories representing greater confidence in presence of cancer. How to handle the 0s and the 2s is the subject of some controversy, described next.
4.12.1 The controversy
Two large clinical studies have been reported in which BI-RADS category data were acquired for > 400,00 screening mammograms interpreted by many (124 in the 1st study) radiologists (Barlow et al. 2004; Fenton et al. 2007). The purpose of the first study was to relate radiologist characteristics to actual performance (e.g., does performance depend on reading volume – the number of cases interpreted per year), so it could be regarded as a more elaborate version of (Beam, Layde, and Sullivan 1996), described in Chapter 2. The purpose of the second study was to determine the effectiveness of computer-aided detection (CAD) in screening mammography.
The reported ROC analyses used the BIRADS assessments labels ordered as follows: \(1 < 2 < 3 < 3+ < 0 < 4 < 5\). The last column of Table 4.3 shows that with this ordering the numbers of cancer per 1000 patients increases monotonically. The CAD study is discussed later, for now the focus is on the adopted BIRADS scale ordering that is common to both studies and which has raised controversy.
| Total number of mammograms | |Mammograms without breast cancer (percent | |Mammograms with breast cancer (percen | ) |Cancers per 1000 screening mammogr | |
|---|---|---|---|---|
| 1: Normal | 356,030 | 355,734 (76.2) | 296 (12.3) | 0.83 |
| 2: Benign finding | 56,614 | 56,533 (12.1) | 81 (3.4) | 1.43 |
| 3: Probably benign, recommend normal or short term follow up | |8,692 | |8,627 (1.8) | |65 (2.7) | |7.48 |
| 3+: Probably benign, recommend immediate follow up | |3,094 | |3,049 (0.7) | |45 (1.9) | |14.54 |
| 0: Need additional imaging evaluation | |42,823 | |41,442 (8.9) | |1,381 (57.5) | |32.25 |
| 4: Suspicious finding, biopsy should be considered | |2,022 | |1,687 (0.4) | |335 (13.9) | |165.68 |
| 5: Highly suggestive of malignancy | |237 | |38 (0.0) | |199 (8.3) | |839.66 |
The use of the BI-RADS ratings shown in Table 4.3 has been criticized (Jiang and Metz 2010) in an editorial titled:
BI-RADS Data Should Not Be Used to Estimate ROC Curves
Since BI-RADS is a clinical rating scheme widely used in mammography, the editorial, if correct, implies that ROC analysis of clinical mammography data is not possible. Since the BI-RADS scale was arrived at after considerable deliberation, the inability to perform ROC analysis with it would strike at the root of clinical utility of the ROC method. The purpose of this section is to express the reasons why I have a different take on this controversy.
It is claimed in the editorial that the Barlow et al. study confuses cancer yield with confidence level and that BI-RADS categories 1 and 2 should not be separate entries of the confidence scale, because both indicate no suspicion for cancer.
I agree with the Barlow et al. suggested ordering of the “2s” as more likely to have cancer than the “1s”. A category-2 means the radiologist found something to report, and the location of the finding is part of the clinical report. Even if the radiologist believes the finding is definitely benign, there is a non-zero probability that a category-2 finding is cancer, as evident in the last column of Table 4.3 (\(1.43 > 0.83\)). In contrast, there are no findings associated with a category-1 report. A paper (Hartmann et al. 2005) titled:
Benign breast disease and the risk of breast cancer
should convince any doubters that benign lesions do have a finite chance of cancer.
The problem with “where to put the 0s” arises only when one tries to analyze clinical BI-RADS data. In a laboratory study the radiologist would not be given the category-0 option. In analyzing a clinical study it is incumbent on the study designer to justify the choice of the rating scale adopted. Showing that the proposed ordering agrees with the probability of cancer is justification – and in my opinion, given the very large sample size this was accomplished convincingly in the Barlow et al. study.
Moreover, the last column of Table 4.3 suggests that any other ordering would violate an important principle, namely, optimal ordering is achieved when each case is rated according to it’s likelihood ratio (defined as the probability of the case being diseased divided by the probability of the case being non-diseased). The likelihood ratio is the “betting odds” of the case being diseased, which is expected to be monotonic with the empirical probability of the case being diseased, i.e., the last column of Table 4.3. Therefore, the ordering adopted in Table 4.3 is equivalent to adopting a likelihood ratio scale and any other ordering would not be monotonic with likelihood ratio.
The likelihood ratio is described in more detail in Chapter 7, which describes ROC fitting methods that yield “proper” ROC curves, i.e., ones that have monotonically decreasing slope as the operating point moves up the curve from (0,0) to (1,1) and therefore do not inappropriately cross the chance diagonal. Key to these fitting methods is adoption of a likelihood ratio scale to rank-order cases. The fitting algorithm implemented in PROPROC software reorders confidence levels assumed by the binormal model, Chapter 7, paragraph following TBA Fig. 20.4. This is analogous to the reordering of the clinical ratings based on cancer rates assumed in Table 4.3. It is illogical to allow reordering of ratings in software but question the same when done in a principled way by a researcher. As expected, the modeled ROC curves in the Barlow publication, their Fig. 4, show no evidence of improper behavior. This is in contrast to a clinical study (about fifty thousands patients spread over 33 hospitals with each mammogram interpreted by two radiologists) using a non-BIRADS 7-point rating scale which yielded markedly improper ROC curves (Pisano et al. 2005) for the film modality when using ROC ratings (not BIRADS). This suggests that use of a non-clinical ratings scale for clinical studies, without independent confirmation of the ordering implied by the scale, is problematical.
The reader might be interested as to reason for the 0-ratings being more predictive of cancer than a 3+ rating, Table 4.3. In the clinic the zero rating implies, in effect, “defer decision, incomplete information, additional imaging necessary”. A zero rating could be due to technical problems with the images: e.g., improper positioning (e.g., missing breast tissue close to the chest wall) or incorrect imaging technique (improper selection of kilovoltage and/or tube charge) making it impossible to properly interpret the images. Since the images are part of the permanent patient record, there are both healthcare and legal reasons why the images need to be optimal. Incorrect technical factors are expected to occur randomly and therefore not predictive of cancer. However, if there is a suspicious finding and the image quality is sub-optimal, the radiologist may be unable to commit to a decision, they may seek additional imaging, perhaps better compression or a slightly different view angle to resolve the ambiguity. Such zero ratings are expected with suspicious findings and are expected to be predictive of cancer.
4.13 Discussion
In this chapter the widely used ratings paradigm was described and illustrated with a sample dataset. The calculation of ROC operating points from this table was explained. A formal notation was introduced to describe the counts in this table and the construction of operating points and an R example was given. I do not wish to leave the impression that the ratings paradigm is used only in medical imaging. In fact the historical reference (Macmillan and Creelman 2004) to the two-question six-point scale in Fig. 4.3 was for a rating study on performance in recognizing odors.
While it is possible to use the equal variance binormal model to obtain a measure of performance, the results depend upon the choice of operating point, and evidence was presented for the generally observed fact that most ROC ratings datasets are inconsistent with the equal variance binormal model. This indicates the need for an extended model, to be discussed in Chapter 6.
The rating paradigm is a more efficient way of collecting the data compared to repeating the binary paradigm with instructions to cause the observer to adopt different fixed thresholds specific to each repetition. The rating paradigm is also more efficient than the 2AFC paradigm – and the rating paradigm is more clinically realistic.
Two controversial but important issues were addressed: the reason for my recommendation for adopting a discrete 6-point rating scale and correct usage of clinical BIRADS ratings in ROC studies. When a clinical scale exists, the empirical disease occurrence rate associated with each rating should be used to order the ratings.
The next step is to describe a model for ratings data. Before doing that, it is necessary to introduce an empirical performance measure, namely the area under the empirical or trapezoidal ROC, which does not require any modeling.
REFERENCES
This type of data representation is sometimes called a frequency table, but frequency means a rate of number of events per some unit of time, so I prefer the clearer term “counts”.↩︎
The estimates in the preceding chapter were for a single operating point. Since the multiple operating points discussed here are correlated –- some of the counts used to calculate them are common to two or more operating points –- the method described in the previous chapter overestimates the confidence intervals. A modeling approach accounts for these correlations and yields narrower confidence intervals.↩︎
Dr. Fraser famously termed – off the record – our statistical analysis in (D. P. Chakraborty et al. 1986) “gobbledygook”.↩︎