Chapter 2 The FROC paradigm and visual search
2.2 Introduction
For diagnostic tasks such as detecting diffuse interstitial lung disease1 where disease location is either irrelevant or implicit, the receiver operating characteristic (ROC) paradigm is appropriate because essential information is not being lost by limiting the radiologist’s response to a single rating per case.
In clinical practice it is not only important to identify if the patient is diseased but to also offer guidance to subsequent care-givers (e.g., the surgeon responsible for resecting a malignant lesion) by identifying other lesion characteristics, e.g., location, type, size and extent.
For localized disease the ROC paradigm limits the collected information to a single rating that categorizes the probability that there is disease somewhere in the patient’s imaged anatomy. “Somewhere” begs the question: if the radiologist believes the disease is “somewhere”, why not have them point to it? In fact they do “point to it” by recording the location(s) of suspicious regions in their clinical report, but the ROC paradigm cannot use the location information.
From the data analyst’s point of view the most troubling issue with ROC analysis when applied to a localization task is that neglect of location information leads to loss of statistical power. That this is a problem can be appreciated from the following simple example comparing expert and non-expert radiologists.
Recall that an ROC paradigm true positive event occurs anytime a diseased patient is diagnosed as diseased: lesion location, if provided, is not considered. Therefore two types of true positive events are possible on diseased cases: those with correct localizations, expected to be associated with expert radiologists, and those with incorrect localizations, expected to be associated with non-experts. The indistinguishability between the two types of true positive events leads to reduced ability to detect a difference between experts and non-experts. The resulting loss of statistical power is highly undesirable since counteracting it would lead to inflated sample size requirements (numbers of readers anc cases) for a contemplated ROC study. Obtaining participating radiologists and finding truth-proven cases are both expensive in radiological observer performance studies 2.
2.3 Location specific paradigms
The term “location-specific” is used for any observer performance paradigm that accounts for lesion location. These paradigms are sometimes incorrectly referred to as lesion-specific (or lesion-level) paradigms. All observer performance methods involve detecting the presence of true lesions and ROC methodology is, in this sense, also lesion-specific. On the other hand location is a characteristic of true and perceived lesions, and methods that account for location are more accurately termed location-specific than lesion-specific.
There are three location-specific paradigms that take into account, to varying degrees, information regarding the locations of perceived lesions:
- the free-response ROC (FROC) (Bunch et al. 1977; Dev P. Chakraborty 1989);
- the location ROC (LROC) (S. Starr et al. 1977; Swensson 1996);
- the region of interest (ROI) (Obuchowski, Lieber, and Powell 2000).
Together with the ROC paradigm they constitute four currently-used observer performance paradigms.
In this book lesion always refers to a true or real lesion. The term suspicious region or perceived lesion is used for any region that, as far as the observer is concerned, has “lesion-like” characteristics. A lesion is a real entity while a suspicious region is a perceived entity.
The 4 panels in Fig. 2.1 show a schematic mammogram interpreted according to these paradigms. The panels are as follows:
- upper left – ROC,
- upper right – FROC,
- lower left – LROC,
- lower right – ROI.
With reference to the top-left panel, the arrows point to two lesions and the three light-shaded crosses indicate suspicious regions 3. A marked suspicious region is indicated by a dark-shaded cross. Evidently the radiologist perceived one of the lesions (the light-shaded cross near the left most arrow), missed the other lesion and mistook two normal structures for lesions, the two light-shaded crosses that are far from any of the lesions. In this example there are three suspicious regions, one of which is close to a real lesion, and one missed lesion.
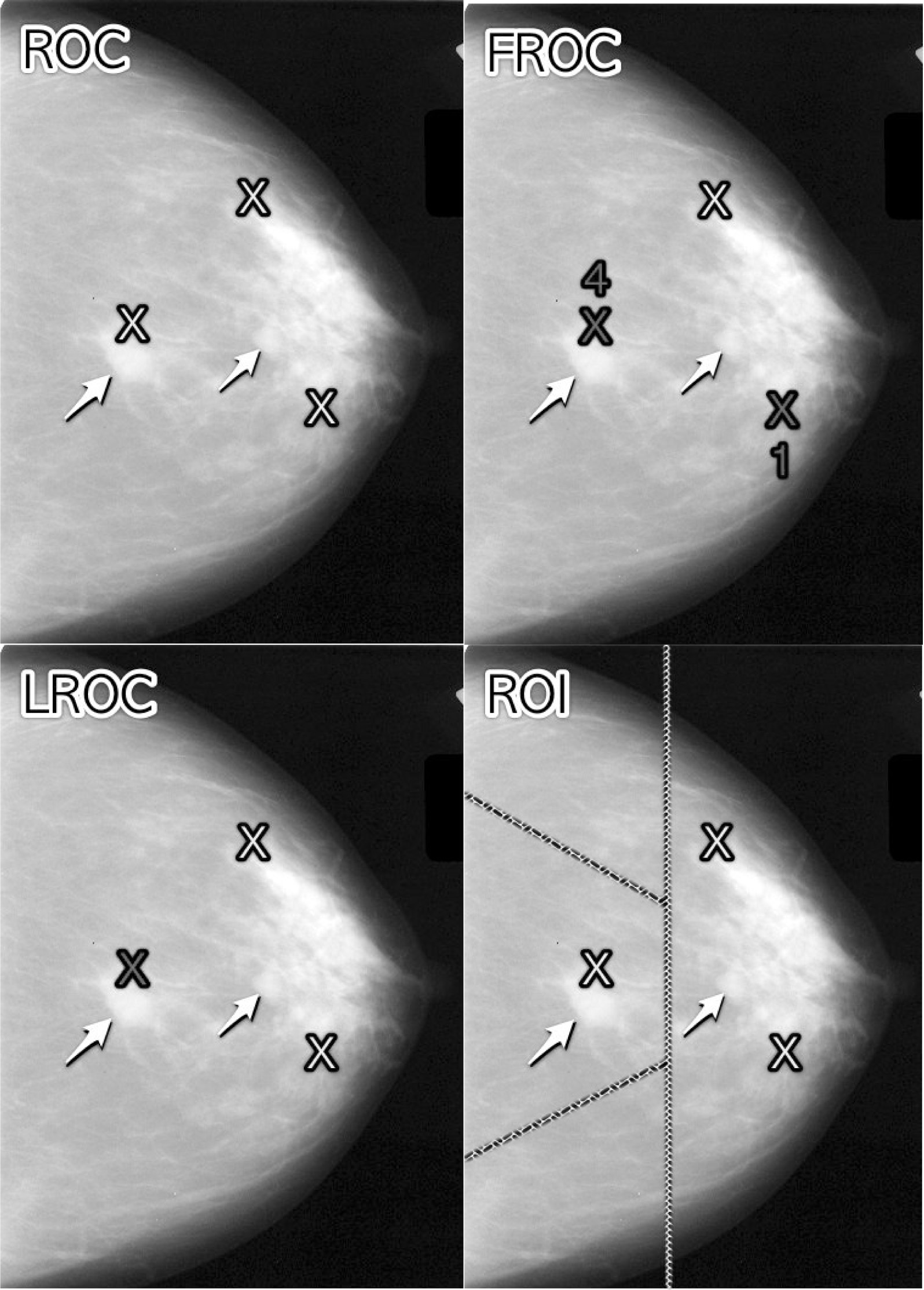
FIGURE 2.1: Schematic showing the four observer performance paradigms. Arrows point to two lesions and light-shaded crosses indicate suspicious regions. Marked suspicious regions are indicated by dark-shaded crosses.
In the ROC paradigm, Fig. 2.1 (top-left panel), the radiologist assigns a single rating indicating the confidence level that there is at least one lesion somewhere in the image. Assuming a 1 – 5 positive directed integer rating scale and if the left-most light-shaded cross is a highly suspicious region then the ROC rating for the image might be 5 (highest confidence for presence of disease somewhere in the image). There are no dark-shaded crosses on this panel as no marking occurs in the ROC paradigm.
In the free-response (FROC) paradigm, Fig. 2.1 (top-right panel), the two dark-shaded crosses indicate suspicious regions that were marked, and the adjacent numbers are the corresponding ratings. Unlike the ROC paradigm where the rating applies to the whole image, in this example each rating applies to a specific suspicious region. Assuming the allowed FROC ratings are integers 1 through 4 two marks are shown, one rated FROC-4, which is close to a true lesion, and the other rated FROC-1, which is not close to any true lesion. The third suspicious region, indicated by the light-shaded cross, was not marked, implying its confidence level did not exceed the threshold for a FROC-1 rating. The marked region rated FROC-4 (the highest FROC confidence level) is likely what caused the radiologist to assign the ROC-5 rating to this image in the ROC paradigm.
In the LROC paradigm, Fig. 2.1 (bottom-left panel), the radiologist rates the confidence that there is at least one lesion somewhere in the image (just as in the ROC paradigm) and then marks the most suspicious region. In this example the rating is LROC-5, the five rating is the same as in the ROC paradigm panel, and the mark is the same mark rated FROC-4 in the FROC paradigm panel. Since it is close to a true lesion in LROC terminology this mark would be recorded as a correct localization. If the mark were not near a lesion it would be recorded as an incorrect localization. Only one mark per image is allowed, and in fact one mark is required on every image, even if the observer does not find any suspicious regions to report.
In the region of interest (ROI) paradigm, Fig. 2.1 (bottom-right panel) the researcher segments the image into a number of regions-of-interest (ROIs) and the radiologist rates each ROI for presence of at least one suspicious region within the ROI. The rating is similar to the ROC rating, except it applies to the ROI, not the whole image. Assuming a 1 – 5 positive directed integer rating scale the ROI at ~9 o’clock might be rated ROI-5 as it contains the most suspicious light-shaded cross, the one at ~11 o’clock might be rated ROI-1 as it does not contain any light-shaded crosses, the one at ~3 o’clock might be rated LROC-2 or LROC-3 (the unmarked light-shaded cross would tend to increase the confidence level) and the one at ~7 o’clock might be rated ROI-14.
Why does the integer FROC rating scale extend from 1 to 4 while the remaining paradigm scales range from 1 to 5? The **absence* of any marked region in FROC conveys information that the case had no reportable suspicious region. In the other paradigms this would need to be indicated using the 1-rating.
2.4 Visual search
Any search task has two components: finding things while not finding irrelevant things, a subtle but important point, and acting on each finding. Two examples of a search tasks are looking for lost car-keys or a milk carton in the refrigerator. Success in a search task is finding the searched for object without finding too many extraneous objects. Acting on the finding could be driving to work or drinking milk from the carton. There is expertise associated with any search task. Husbands are notoriously bad at finding the milk carton in the refrigerator (analogy due to Dr. Krupinski at an SPIE course taught jointly with the author).
Likewise, a medical imaging search task has two components: finding lesions and acting on each finding. “Finding” is the actual term used by radiologists in their clinical reports. Acting on the finding involves determining if it is sufficiently suspicious for cancer to warrant reporting and further patient follow-up. Such a region is marked and rated for confidence that it is a malignant lesion.
The radiologist does not know a-priori if the patient is diseased and, if diseased, how many lesions may be present. In the breast-screening context it is known that about 5 out of 1000 patients have cancers, so 99.5% of the time odds are that the patient has no malignant lesions5. Considerably search expertise is needed for the radiologist to mark malignant lesions with high probability while not generating too many false marks.
At my former institution (University of Pittsburgh) the radiologists digitally outline and annotate (describe) suspicious region(s) that are found. As one would expect from the low prevalence of breast cancer in the screening context and assuming expert-level radiologist interpretations, about 90% of breast cases do not generate any marks. About 10% of cases generate one or more marks and are recalled for further comprehensive imaging (termed diagnostic workup). Of marked cases about 90% generate one mark, about 10% generate 2 marks, and a rare case generates 3 or more marks (Dr. David Gur, private communication, ca. 2015).
Conceptually, a mammography report consists of the locations of regions that exceed the threshold and the corresponding levels of suspicion, reported as a Breast Imaging Reporting and Data System (BIRADS) rating. The BIRADS rating (typically integers 1 through 5) is actually assigned after the diagnostic workup following a screening BIRADS-0 rating. The screening rating itself is binary: BIRADS-0 for recall (the patient is recalled for a diagnostic workup to determine the final 1-5 BIRADS rating) or BIRADS-1 for normal or no abnormality detected (the patient comes back about a year later for the next screening examination).
The FROC paradigm in medical imaging is a visual search task.
2.4.1 Proximity criterion and scoring the data
In the first quasi-clinical application of the FROC paradigm (D. P. Chakraborty et al. 1986) the marks and ratings were indicated by a grease pencil on an acrylic overlay aligned, in a reproducible way, to the CRT displayed chest image of an anthropomorphic chest phantom with superposed simulated lesions. Credit for a correct detection and localization, termed a lesion-localization or LL-event6, was given only if a mark was sufficiently close (as per the adopted proximity criterion, see below) to an actual diseased region; otherwise, the observer’s mark was scored as a non-lesion localization or NL-event.
The use of ROC terminology such as true positives or false positives to describe FROC data is not conducive to clarity and is strongly discouraged.
Definitions:
- NL = non-lesion localization, i.e., a mark that is not close to any lesion
- LL = lesion localization, i.e., a mark that is close to a lesion
One adopts an acceptance radius (for spherical lesions) or proximity criterion (the more general case). What constitutes “close enough” is a clinical decision the answer to which depends on the application. It is not necessary for two radiologists to point to the same pixel in order for them to agree that they are seeing the same suspicious region. Likewise, two physicians – e.g., the radiologist finding the lesion on an x-ray and the surgeon responsible for resecting it – do not have to agree on the exact center of a lesion in order to appropriately assess and treat it. Clinical considerations should be used to determine if a mark actually localized the lesion with sufficient accuracy. When in doubt, the researcher should ask an independent radiologist (i.e., not one used in the observer study) how to score ambiguous marks. A rigid definition of the proximity criterion should not be used.
For roughly spherical nodules a simple rule can be used. If a circular lesion is 10 mm in diameter, one can use the “touching-coins” analogy to determine the criterion for a mark to be classified as lesion localization. Each coin is 10 mm in diameter so if they touch their centers are separated by 10 mm and the rule is to classify any mark within 10 mm of an actual lesion center as a LL mark, and if the separation is greater the mark is classified as a NL mark. A recent paper (Dobbins III et al. 2016) using FROC analysis gives more details on appropriate proximity criteria in the clinical context in a study involving both volumetric (CT) and 2D chest images.7
2.4.2 Multiple marks in the same vicinity
Multiple marks near the same vicinity are rarely encountered with radiologists, especially if the perceived lesion is mass-like. 8 However, algorithmic readers, such as computer aided detection (CAD) algorithms, tend to find multiple regions in the same area. Algorithm designers generally incorporate a clustering step to reduce overlapping regions to a single region and assign the highest rating to it (i.e., the rating of the highest rated mark, not the rating of the closest mark. 9
2.4.3 Historical context
The term “free-response” was coined by (Egan, Greenberg, and Schulman 1961) to describe a task involving the detection of brief audio tone(s) against a background of noise. The tone(s) could occur at any instant within an active listening interval, defined by an indicator light bulb that is turned on. The listener’s task was to respond by pressing a button at the specific instant(s) when a tone(s) was heard. The listener was uncertain how many true tones could occur in an active listening interval and when they might occur. Therefore, the number of responses (button presses) per active interval was a priori unpredictable: it could be zero, one or more. The study did not require the listener to rate each button press, but apart from this difference and with two-dimensional images replacing the listening intervals, the acoustic signal detection study is analogous to medical imaging search tasks.
2.5 The FROC plot
The free-response receiver operating characteristic (FROC) plot was introduced (Miller 1969) as a way of visualizing performance in the free-response auditory tone detection task.
In the medical imaging context, assuming the mark rating pairs have been classified as NLs (non-lesion localizations) or LLs (lesion localizations):
Non-lesion localization fraction (NLF) is defined as the total number of NLs rated at or above a threshold rating divided by the total number of cases.
Lesion localization fraction (LLF) is defined as the total number of LLs rated at or above the same threshold rating divided by the total number of lesions.
The FROC plot is defined as that of LLF (ordinate) vs. NLF as the threshold is varied.
The upper-right-most operating point is termed the observed end-point and its coordinates are denoted \((\text{NLF}_{\text{max}}, \text{LLF}_{\text{max}})\).
The rating can be any real number, as long as higher values are associated with higher confidence levels.
If integer ratings are used then in a four-rating FROC study at most 4 FROC operating points will result: one corresponding to marks rated 4s; another corresponding to marks rated 4s or 3s; another to the 4s, 3s, or 2s; and finally the 4s, 3s, 2s, or 1s. 10.
If continuous ratings are used, the procedure is to start with a very high threshold so that none of the ratings exceed the threshold and then to gradually lower the threshold. Every time the threshold crosses the rating of a mark, or possibly multiple marks, the total count of LLs and NLs exceeding the threshold is divided by the appropriate denominators yielding the “raw” FROC plot. For example, when an LL rating just exceeds the threshold, the operating point jumps up by 1/(total number of lesions), and if two LLs simultaneously just exceed the threshold the operating point jumps up by 2/(total number of lesions). If an NL rating just exceeds the threshold, the operating point jumps to the right by 1/(total number of cases). If an LL rating and a NL rating simultaneously just exceed the threshold, the operating point moves diagonally, up by 1/(total number of lesions) and to the right by 1/(total number of cases). The cumulating procedure is very similar to the manner in which ROC operating points were calculated, the only differences being in the quantities being cumulated and the relevant denominators.
Empirical plot:
A plot is termed empirical if is based on the observed operating points: one simply connects adjacent operating points (including the origin) with straight lines.
Chapter 3 describes the empirical FROC and other empirical operating characteristics in more detail.
2.5.1 Illustration with a dataset
The following code uses dataset04 (Zanca et al. 2009) in RJafroc to illustrate an empirical FROC plot. The dataset has 5-treatments and 4 readers, so one could generate 20 plots. In this example I have selected treatment 1 and reader 1.
ret <- PlotEmpiricalOperatingCharacteristics(
dataset04, trts = 1, rdrs = 1, opChType = "FROC")
print(ret$Plot)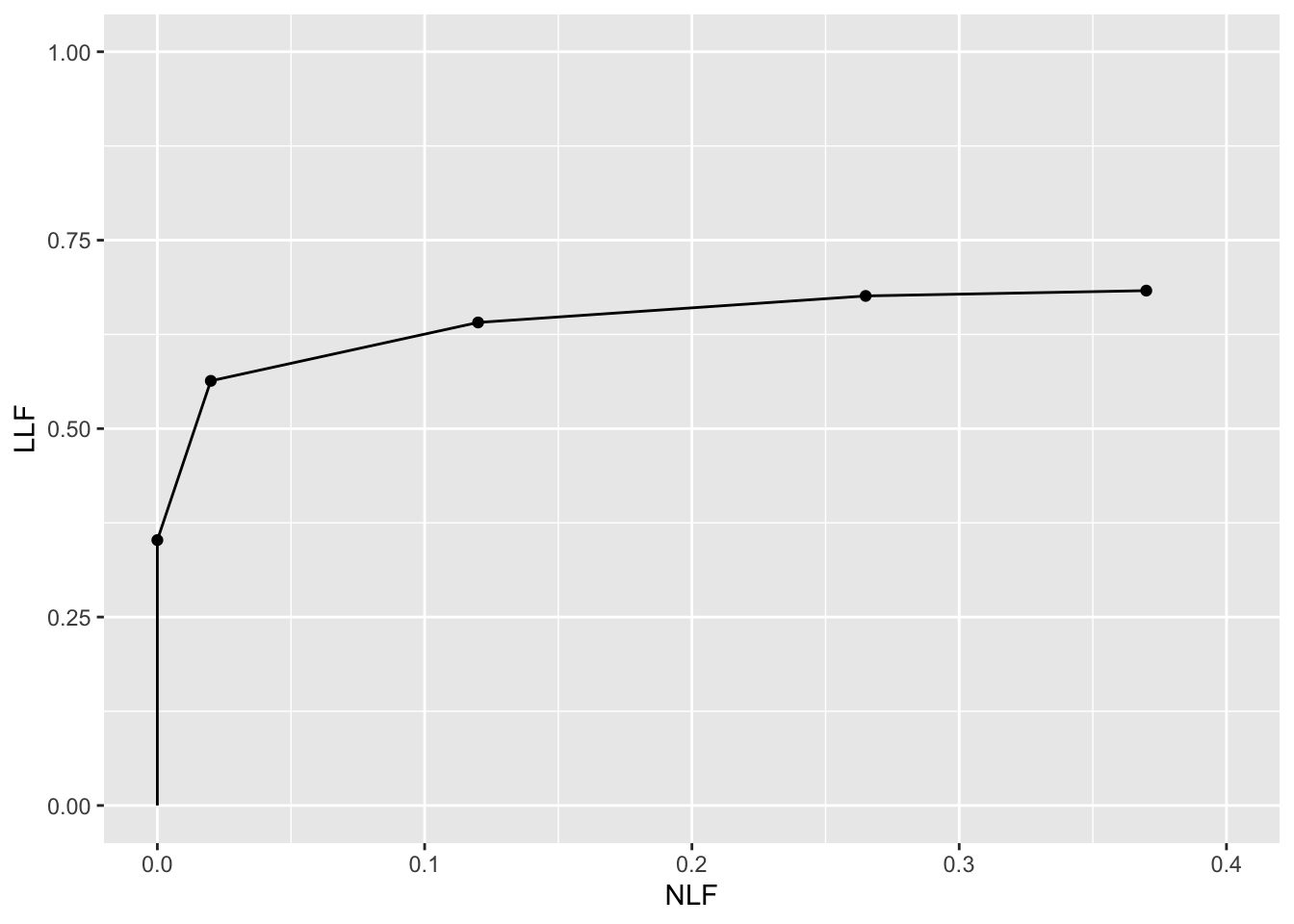
FIGURE 2.2: Empirical FROC plot for dataset04, treatment 1 and reader 1.
The study in question was a 5 rating FROC study. The lowest non-trivial point (i.e., not counting the origin which is common to all FROC plots) corresponds to marks rated 5, the next higher one corresponds to marks rated 4 or 5, etc. FROC plots may vary widely in shape but they share the common characteristic, namely the operating point cannot move downward or to the left as one cumulates lower confidence level marks.
The above plot is termed an empirical plot as it consists of the empirical (observed) operating points connected by straight line segments. A model based plot would be termed a predicted plot.
2.6 The Astronomical Analogy
Consider the sun, regarded as a “lesion” to be detected, with two daily observations spaced 12 hours apart, so that at least one observation period is bound to have the sun in the sky. Furthermore assume the observer knows his GPS coordinates and has a watch that gives accurate local time, from which an accurate location of the sun can be deduced. Assuming clear skies and no obstructions to the view, the sun will always be correctly located and no rational observer will ever generate a non-lesion localization or NL, i.e., no region of the sky will be erroneously “marked” as being the sun.
FROC curve implications of this analogy are:
- Each 24-hour day corresponds to two “trials” in the (Egan, Greenberg, and Schulman 1961) sense, or two cases – one diseased and one non-diseased – in the medical imaging context.
- The denominator for calculating LLF is the total number of AM days, and the denominator for calculating NLF is twice the total number of 24-hour days.
- Most important, \(\text{LLF}_{\text{max}} = 1\) and \(\text{NLF}_{\text{max}} = 0\).
In fact, even when the sun is not directly visible due to heavy cloud cover, since the actual location of the sun can be deduced from the local time and GPS coordinates, the rational observer will still “mark” the correct location of the sun and not make any false sun localizations. Consequently, even in this example \(\text{LLF}_{\text{max}} = 1\) and \(\text{NLF}_{\text{max}} = 0\).
The conclusion is that in a task where a target is known to be present in the field of view and its location is known the observer will always achieve \(\text{LLF}_{\text{max}} = 1\) and \(\text{NLF}_{\text{max}} = 0\). LLF and NLF subscripted "max" because by randomly choosing to not mark the position of the sun, even though it is visible, the observer can “walk down” the y-axis of the FROC plot, eventually reaching \(LLF = 0\) and \(NLF = 0\), demonstrating that a continuous FROC curve from the origin to (0,1) can, in fact, be realized.
Now consider a fictitious otherwise earth-like planet where the sun can be at random positions rendering GPS coordinates and the local time useless. All one knows is that the sun is somewhere in the upper or lower hemispheres subtended by the sky. If there are no clouds and consequently one can see the sun clearly during daytime, a rational observer will still correctly locate the sun while not marking the sky with any incorrect sightings, so \(\text{LLF}_{\text{max}} = 1\) and \(\text{NLF}_{\text{max}} = 0\). This is because, in spite of the fact that the expected location is unknown, the high contrast sun is enough the trigger peripheral vision, so that even if the observer did not start out looking in the correct direction, peripheral vision will guide the observer’s gaze to the correct location.
The implication of this is that a fundamentally different mechanism is involved from that considered in conventional (i.e., ROC) observer performance methodology, namely search.
Search describes the process of finding lesions while not finding non-lesions; search performance is the ability to find lesions while not finding non-lesions.
Think of the eye as two cameras: a low-resolution camera (peripheral vision) with a wide field-of-view plus a high-resolution camera (foveal vision) with a narrow field-of-view. If one were limited to viewing with the high-resolution camera one would spend so much time steering the high-resolution narrow field-of-view camera from spot-to-spot that one would have a hard time finding the desired stellar object. Having a single high-resolution narrow field of view vision would also have negative evolutionary consequences as one would spend so much time scanning and processing the surroundings that one would miss dangers or opportunities. Nature has equipped us with essentially two cameras; the first low-resolution camera is able to “digest” large areas of the surroundings and process it rapidly so that if danger (or opportunity) is sensed, then the eye-brain system rapidly steers the second high-resolution camera to the appropriate location. This is Nature’s way of optimally using the eye-brain system. For a similar reason astronomical telescopes come with a wide field of view lower magnification “spotter scope”.
When cloud cover completely blocks the fictitious random-position sun there is no stimulus to trigger the peripheral vision system to guide the fovea to the correct location. The observer is reduced to guessing and is led to different conclusions depending upon the benefits and costs involved. If, for example, the guessing observer earns a dollar for each LL and is fined a dollar for each NL, then the observer will likely not make any marks as the chance of winning a dollar is much smaller than losing many dollars. For this observer \(\text{LLF}_{\text{max}} = 0\) and \(\text{NLF}_{\text{max}} = 0\), i.e., the operating point is “stuck” at the origin. On the other hand if the observer is told every LL is worth a dollar and there is no penalty to NLs, then with no risk of losing the observer will “fill up” the sky with false marks.
The analogy is not restricted to the sun, which one might argue is an almost infinite signal-to-noise-ratio (SNR) object and therefore atypical. Consider finding stars or planets. In clear skies one can still locate bright stars and planets like Venus or Jupiter. With less bright stars and/or obscuring clouds, there will be false-sightings and the FROC plot could approach a flat horizontal line at ordinate equal to zero, but TBA the observer will not fill up the sky with false sightings of a desired star. Why?
False sightings of objects in astronomy do occur. Finding a new astronomical object is a search task, where, as always, one can have two outcomes, correct localization or incorrect localizations.
2.7 Implications for models of visual search
[This section will make more sense after reading Chapter 6 on the Radiological Search Model (RSM).]
The Astronomical Analogy elucidates some crucial features of visual search. In the medical imaging context visual search is defined as finding lesion(s) given that their locations are unknown while minimizing finding non-lesions. As shown in the previous section, if lesion contrast is high then the observer’s visual system will guide the eye to the correct location(s). The result is that incorrect localizations and missed lesions will rarely occur. In terms of the RSM, as lesion contrast, i.e., \(\mu\), increases the number of non-lesion localizations, i.e., \(\lambda\), decreases, and the fraction of detected lesions, i.e., \(\nu\), approaches unity. This tandem behavior will be accounted for in the formulation of the RSM, in particular the distinction made in Chapter 6 between physical and intrinsic RSM \(\lambda\) and \(\nu\) parameters, see in particular Sections 6.5 and 6.6.
2.8 Discussion
The FROC paradigm has been confused by loose terminology and misconceptions about visual search, the FROC paradigm and the FROC curve. Some examples follow
- Loose terminology:
- Using ROC paradigm terms, such as true positive and false positive, that apply to the whole case, to describe location-specific terms such as lesion and non-lesion localizations, that apply to regions of the image.
- Using the FROC-1 rating to mean in effect “I see no signs of disease in this image” when in fact it should be used as the lowest level of a reportable suspicious region. The former usage amounts to wasting a confidence level.
- Using the term “lesion-specific” to describe location-specific paradigms.
- Using the term “lesion” when one means a “suspicious region” that may or may not be a true lesion.
- Using ROC paradigm terms, such as true positive and false positive, that apply to the whole case, to describe location-specific terms such as lesion and non-lesion localizations, that apply to regions of the image.
- Misconceptions:
- A fundamental misunderstanding of search performance is embodied in the statement “CAD is perfect at search because it looks at everything”.
- Showing FROC curves as reaching the unit ordinate – which is the exception rather than the rule.
- The belief that FROC curves extend to very large (potentially infinite) values along the abscissa and all the observer has to do to access this region is to lower the reporting threshold.
The FROC plot is historically the first proposed way of visually summarizing FROC data. The next chapter deals with all empirical operating characteristics that can be defined from an FROC dataset that have evolved over the years.
REFERENCES
Diffuse interstitial lung disease refers to disease within both lungs that affects the interstitium or connective tissue that forms the support structure of the lungs’ air sacs or alveoli. When one inhales, the alveoli fill with air and pass oxygen to the blood stream. When one exhales, carbon dioxide passes from the blood into the alveoli and is expelled from the body. When interstitial disease is present, the interstitium becomes inflamed and stiff, preventing the alveoli from fully expanding. This limits both the delivery of oxygen to the blood stream and the removal of carbon dioxide from the body. As the disease progresses, the interstitium scars with thickening of the walls of the alveoli, which further hampers lung function. Diffuse interstitial lung disease is spread through and confined to the lung.↩︎
Numerical examples of the loss of statistical power of ROC analysis as compared to a method that credits correct localizations are here.↩︎
These were obtained using an eye-tracking apparatus↩︎
The ROIs could be clinically driven descriptors of location, such as “apex of lung” or “mediastinum”, and the image does not have to have lines showing the ROIs (which would be distracting to the radiologist). The number of ROIs per image can be at the researcher’s discretion and there is no requirement that every case have the same number of ROIs.↩︎
The probability of benign suspicious regions is much higher (Ernster 1981), about 13% for women aged 40-45.↩︎
The terminology for this paradigm has evolved. Older publications and some newer ones refer to this as a true positive (TP) event, thereby confusing a ROC paradigm term that does not involve search and localization with one that does.↩︎
Generally the proximity criterion is more stringent for smaller lesions than for larger one. However, for very small lesions allowance is made so that the criterion does not penalize the radiologist for normal marking “jitter”. For 3D images the proximity criteria is different in the x-y plane vs. the slice thickness axis.↩︎
The exception would be if the perceived lesions were speck-like objects in a mammogram, and even here radiologists tend to broadly outline the region containing perceived specks – they do not mark individual specks with great precision.↩︎
The highest rating gives full and deserved credit for the correct localization. Other marks in the same vicinity with lower ratings need to be discarded from the analysis; specifically, they should not be classified as NLs, because each mark has successfully located the true lesion to within the clinically acceptable criterion, i.e., any one of them is a good decision because it would result in a patient recall and point further diagnostics to the true location.↩︎
I have seen publications that describe a data collection process where the “1” rating is used to mean, in effect, that the observer sees nothing to report in the image, i.e., to mean “let’s move on to the next image”. This amounts to wasting a confidence level. The FROC data collection interface should present an explicit “next-image” option and reserve the “1” rating to mean the lowest reportable confidence level.↩︎