Chapter 2 ROC data format
2.2 Introduction
The JAFROC Excel data format was adopted circa. 2006. The purpose of this chapter is to explain the format of this file and how to read this file into a dataset object suitable for analysis using the RJafroc package.
In the ROC paradigm the observer assigns a rating to each image. A rating is an ordered numeric label, and, in our convention, higher values represent greater certainty or confidence for presence of disease. Location information associated with the disease, if applicable, is not collected.
2.3 Note to existing users
The Excel file format has recently undergone changes involving three additional columns in the
Truthworksheet. These are needed for generalization to other data collection paradigms and for better data entry error control.RJafrocwill work with original format Excel files provided theNewExcelFileFormatflag inDfReadDataFileis set toFALSE, which is the default (see following help page).Going forward, one should use the new format, described below, and use
NewExcelFileFormat = TRUEto read the file.

2.5 Worksheets in the Excel file
The illustrations in this chapter are for Excel file
R/quick-start/rocCr.xlsxin the project directory. I assume the reader has forked theRJafrocQuickStartrepository. See Section 1.6 for how to download all files and code in thisbookdownbook to your computer.This is a toy file, i.e., a small made-up dataset used to illustrate essential features of the data format.
The Excel file has three worksheets:
Truth,NL(orFP) andLL(orTP). The worksheet names are case insensitive.
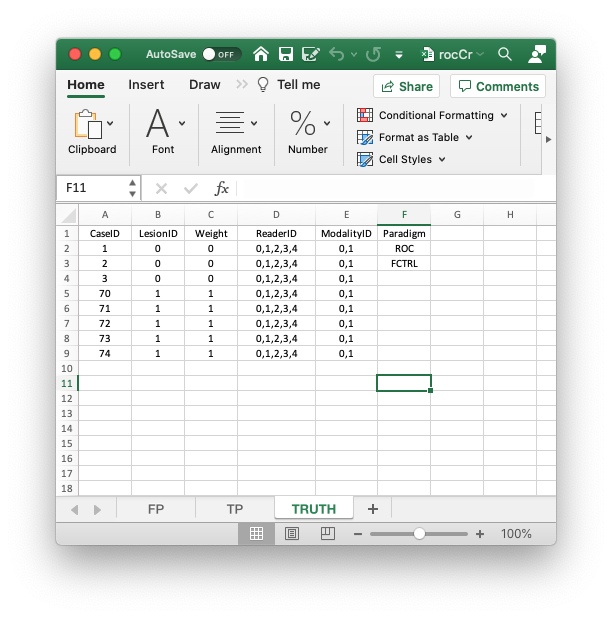
2.5.1 The Truth worksheet
The Truth worksheet shown above contains 6 columns: CaseID, LesionID, Weight, ReaderID, ModalityID and Paradigm. These names are case sensitive.
CaseID: unique integers, one per case, representing the cases in the dataset. In the current dataset, the non-diseased cases are labeled1,2and3, while the diseased cases are labeled70,71,72,73and74. The values do not have to be consecutive integers; they need not be ordered; the only requirement is that they be unique integers. It is recommended that small integers be used.LesionID: integers 0 or 1, with each 0 representing a non-diseased case and each 1 representing a diseased case.Weight: this field is not used for ROC data.ReaderID: a comma-separated string containing the reader (i.e., radiologist or observer) labels, each represented by a unique integer, that have interpreted the case. In the example shown below each cell has the value0, 1, 2, 3, 4meaning each of these readers has interpreted all cases. With multiple readers each cell in this column has to be text formatted as otherwise Excel will not accept it. Select the worksheet, thenFormat-Cells-Number-Text-OK. It is highly recommended that small equal-length integers, properly ordered, be used, as otherwise the output will not be aesthetically pleasing (the code will work, but the output will be harder to interpret). For example0, 1, 2, 3, 4is preferred to00, 10, 20, 30, 40and to1, 3, 2, 0, 4.ModalityID: a comma-separated string containing the modality labels, each represented by a unique integer. In the example each cell has the value0, 1meaning this is a two-modality study. As above, with multiple modalities each cell has to be text formatted as otherwise Excel will not accept it. It is highly recommended that small equal-length integers, properly ordered, be used.Paradigm: this column contains two cells,ROCandFCTRL. It means that this is an ROC dataset and the study design is factorial (or fully-crossed), i.e., each reader interprets each case in each modality.
2.5.2 Comments on the Truth worksheet
There are 5 diseased cases in the dataset (the number of 1’s in the LesionID column of the Truth worksheet). There are 3 non-diseased cases in the dataset (the number of 0’s in the LesionID column). There are 5 readers in the dataset (each cell in the ReaderID column contains the string 0, 1, 2, 3, 4). There are 2 modalities in the dataset (each cell in the ModalityID column contains the string 0, 1).
2.5.3 The FP/NL worksheet
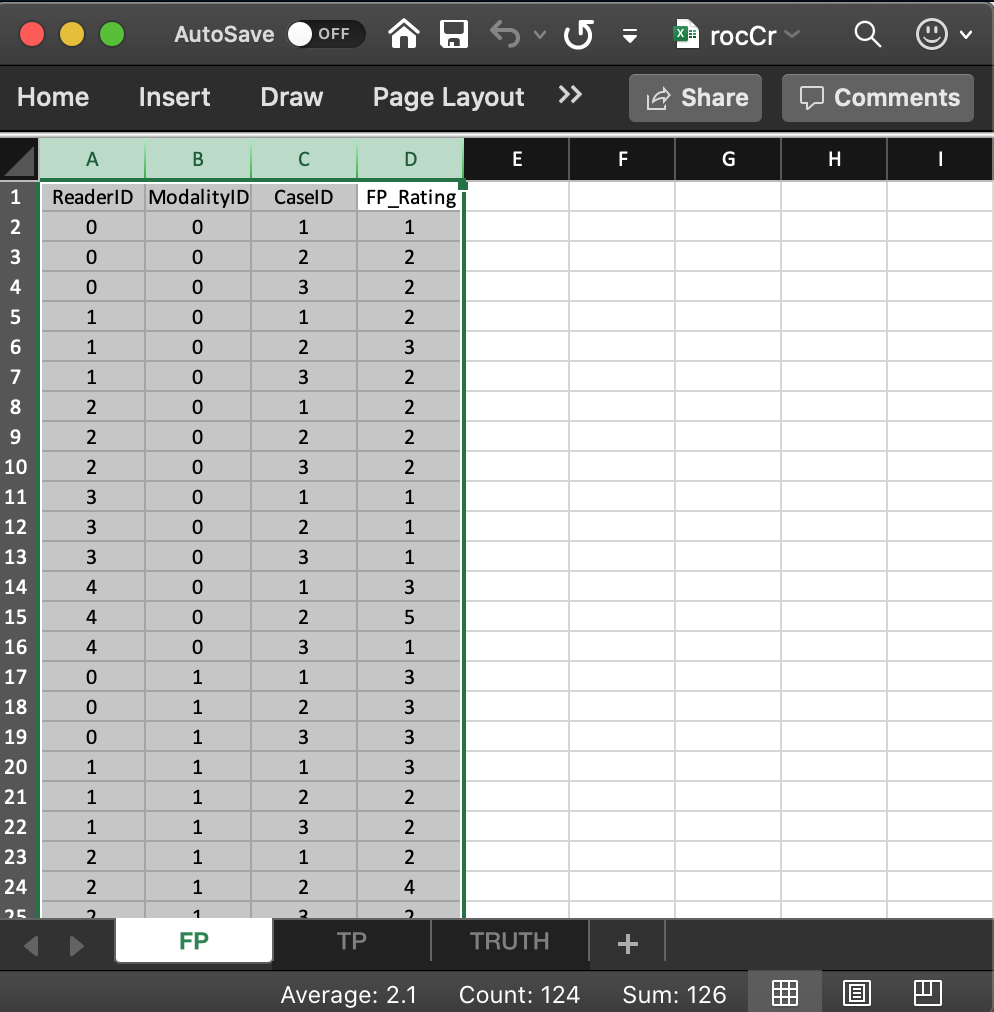
The FP/NL worksheet consists of 4 columns, each of length 30 (i.e., # of modalities x number of readers x number of non-diseased cases). The (case sensitive) column names and meanings are as follows:
ReaderID: the reader labels:0,1,2,3and4. Each reader label occurs 6 times (i.e., # of modalities x number of non-diseased cases).ModalityID: the modality or treatment labels:0and1. Each label occurs 15 times (i.e., # of readers x number of non-diseased cases).CaseID: the case labels for non-diseased cases:1,2and3. Each label occurs 10 times (i.e., # of modalities x # of readers). The label of a diseased case cannot occur in the FP worksheet. If it does the software generates an error.FP_Rating: the (floating point) ratings of non-diseased cases. Each row of this worksheet contains a rating corresponding to the values ofReaderID,ModalityIDandCaseIDfor that row.
2.5.4 The TP/LL worksheet
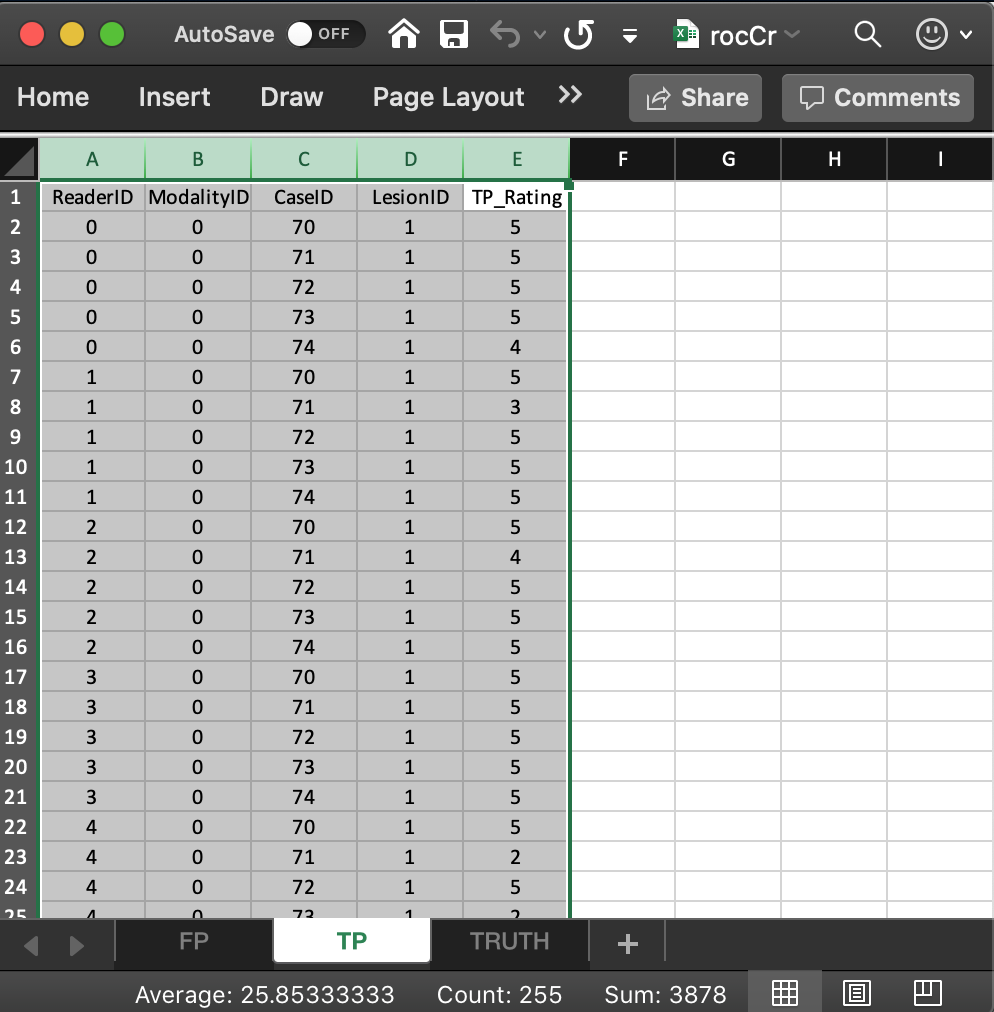
The TP/LL worksheet consists of 5 columns, each of length 50 (i.e., # of modalities x number of readers x number of diseased cases). The (case sensitive) column names and meanings are as follows:
ReaderID: the reader labels:0,1,2,3and4. Each reader label occurs 10 times (i.e., # of modalities x number of diseased cases).ModalityID: the modality or treatment labels:0and1. Each label occurs 25 times (i.e., # of readers x number of diseased cases).LesionID: For an ROC dataset this column contains fifty 1’s (each diseased case has one lesion).CaseID: the case labels for non-diseased cases:70,71,72,73and74. Each label occurs 10 times (i.e., # of modalities x # of readers). For an ROC dataset the label of a non-diseased case cannot occur in the TP worksheet. If it does the software generates an error.TP_Rating: the (floating point) ratings of diseased cases. Each row of this worksheet contains a rating corresponding to the values ofReaderID,ModalityID,LesionIDandCaseIDfor that row.
2.6 Reading the Excel file
The following code uses the function DfReadDataFile to read the Excel file and save it to object x.
x <- DfReadDataFile("R/quick-start/rocCr.xlsx", newExcelFileFormat = TRUE)newExcelFileFormatis set toTRUEas otherwise columns D - F in theTruthworksheet are ignored and the dataset is assumed to be factorial, withdataType“automatically” determined from the contents of the FP and TP worksheets. 1Flag
newExcelFileFormat = FALSE, the default, is for compatibility with the original JAFROC format Excel format, which did not have columns D - F in theTruthworksheet. Its usage is deprecated.
2.7 Structure of dataset object
Most users will not need to be concerned with the internal structure of the dataset object x. For those interested in it, for my reference, and for ease of maintenance of the software, this is deferred to Section 11.2.1.
The assumptions underlying the “automatic” determination could be defeated by data entry errors.↩︎