Chapter 40 Localization - classification tasks
40.1 TBA How much finished
10%
40.2 Introduction
TBA: This project is a works-in-progress.
40.3 Abbreviations
- Correct-localization correct-classification = CL-CC
- Correct-localization incorrect-classification = CL-IC
- Incorrect-localization classification not applicable = IL-NA
40.4 History and basic idea
This project started with a request to extend localization analysis software RJafroc to localization-classification tasks. Since this is new research the required data format is not in the RJafroc documentation. Some familiarity with basic localization task analysis is assumed.
The basic idea is that spatial localization is a special case of localization-with-classification. CL-CC marks are put in TP sheet and other are put in FP sheet.
40.5 First example, File1.xlsx
- This example is implemented in file
File1.xlsx. - There are four classes of lesions:
C1,C2,C3andC4. - The rating scale is 1 - 10 and positive-directed.
- The dataset has 3 cases: 9, 17 and 19.
40.5.1 Truth sheet
This has the ground truth of for cases and lesions, and specifies their class types.
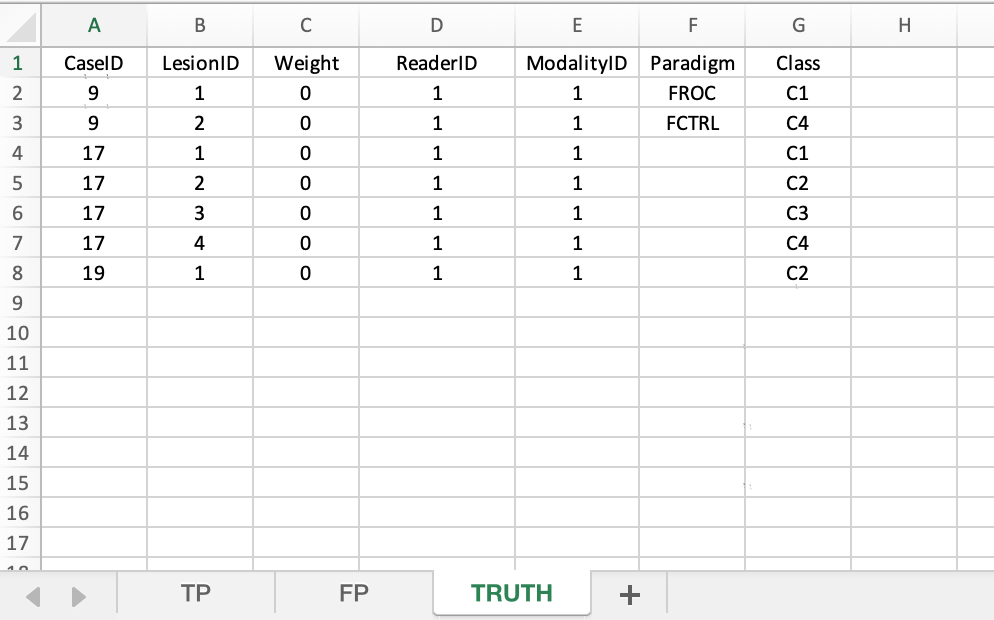
FIGURE 40.1: Truth worksheet for File1.xlsx
- Case 9 has two lesions, with classes
C1andC4. - Case 17 has four lesions, with classes
C1,C2,C3andC4. - Case 19 has one lesion, with class
C2.
40.5.2 TP sheet
This holds CL-CC marks.
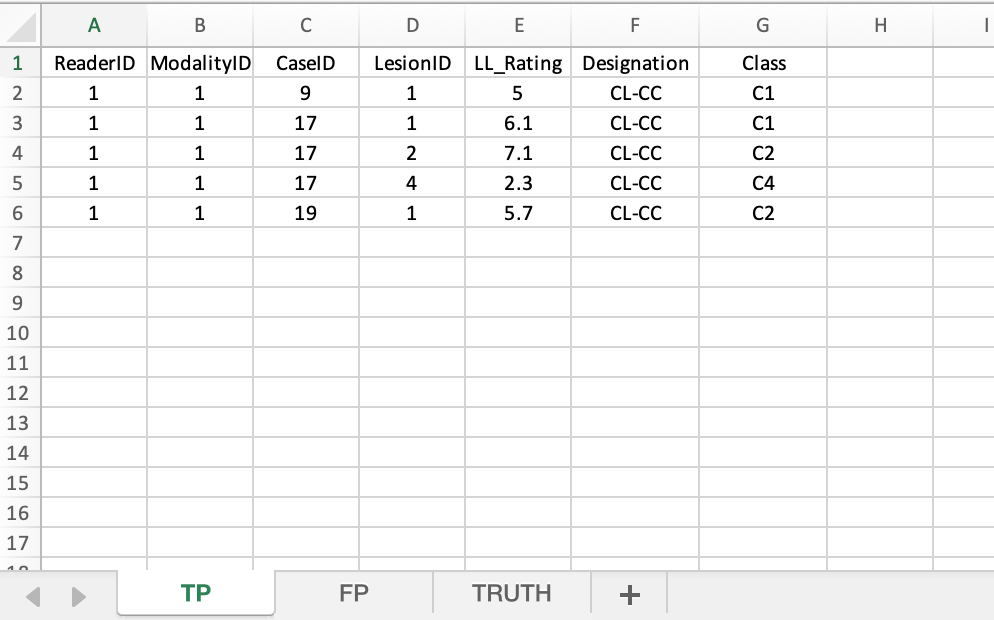
FIGURE 40.2: TP worksheet for File1.xlsx
40.5.2.1 Case 9
- Lesion
C1,lesionID= 1, CL-CC mark rated 5.
40.5.2.2 Case 17
- Lesion
C1,lesionID= 1, CL-CC mark rated 6.1. - Lesion
C2,lesionID= 2, CL-CC mark rated 7.1. - Lesion
C4,lesionID= 4, CL-CC mark rated 2.3.
40.5.2.3 Case 19
- Lesion
C2,lesionID= 1, CL-CC mark rated 5.7.
40.5.3 FP sheet
- This holds IL-NA and CL-IC marks.
ClassTrueis the true class of the lesion.ClassDxis the indicated or diagnosed class of the lesion.
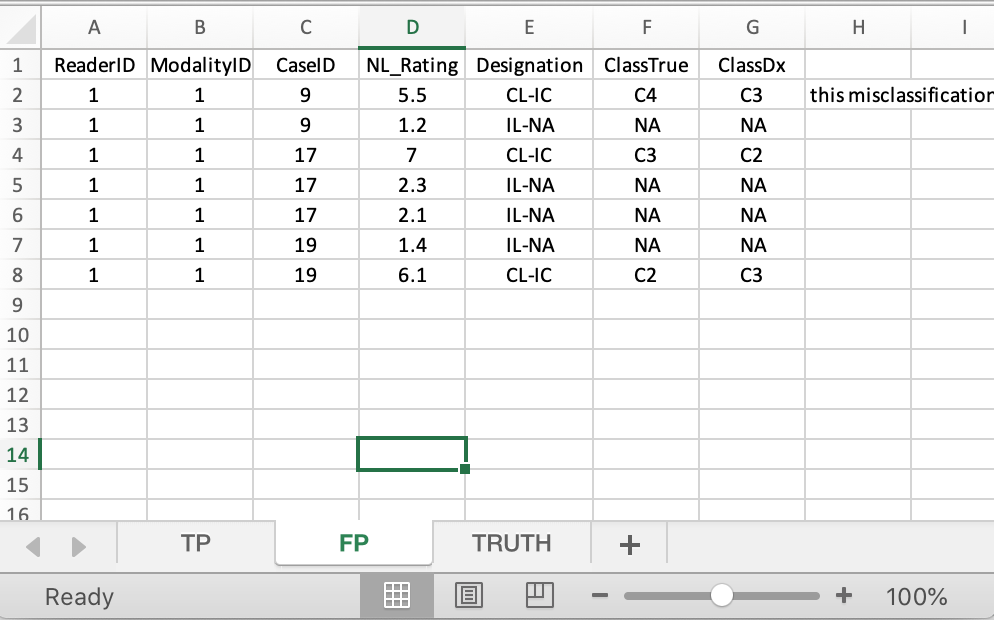
FIGURE 40.3: FP worksheet for File1.xlsx
40.5.3.1 Case 9
- CL-IC mark rated 5.5,
C2classified asC3. - IL-NA mark rated 1.2.
40.5.3.2 Case 17
- CL-IC mark rated 7,
C3classified asC2. - IL-NA mark rated 2.3.
- IL-NA mark rated 2.1.
40.5.3.3 Case 19
- IL-NA mark rated 1.4.
- CL-IC mark rated 6.1,
C2classified asC3.
40.5.4 The two ratings arrays
fileName <- "R/CH83-ClassificationTask/File1.xlsx"
x <- DfReadDataFile(fileName = fileName)
x$ratings$NL[1,1,,]
#> [,1] [,2] [,3]
#> [1,] 5.5 1.2 -Inf
#> [2,] 7.0 2.3 2.1
#> [3,] 1.4 6.1 -Inf
x$ratings$LL[1,1,,]
#> [,1] [,2] [,3] [,4]
#> [1,] 5.0 -Inf -Inf -Inf
#> [2,] 6.1 7.1 -Inf 2.3
#> [3,] 5.7 -Inf -Inf -InfThe FOM is shown next:
40.6 Second example, File2.xlsx
I increased the LL rating for case 19 to 10; this should increase the FOM. This example is implemented in file File2.xlsx.
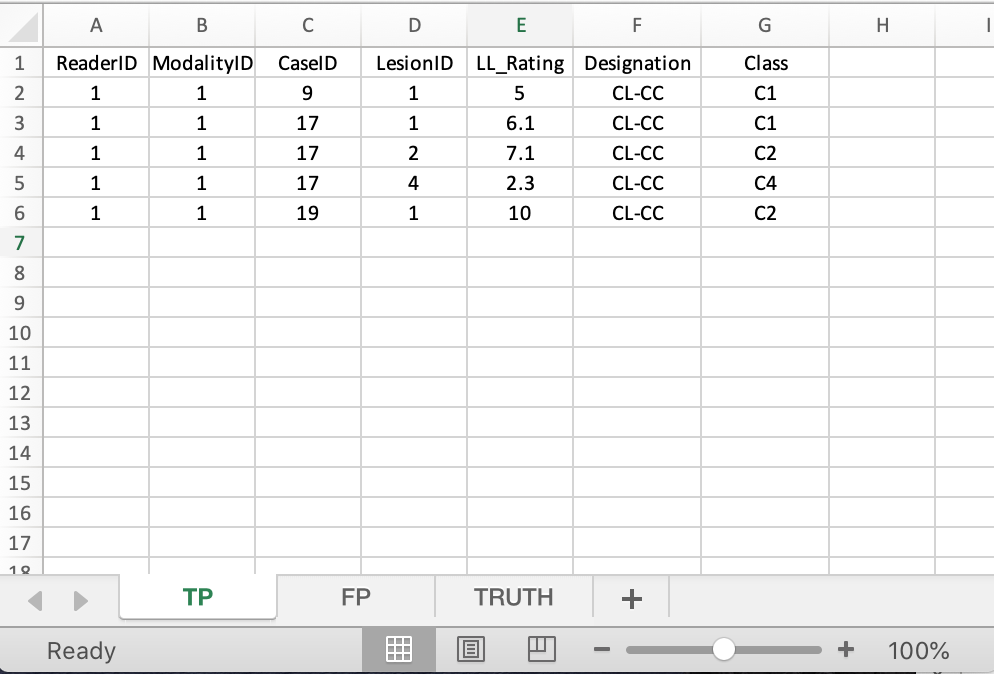
FIGURE 40.4: TP worksheet for File2.xlsx
40.7 Third example, File3.xlsx
Starting with original file, I transferred a CL-IC for case 17 to the TP sheet, where it is a CL_CC mark. This should increase the FOM as credit is given for CL-CC. This example is implemented in file File3.xlsx.
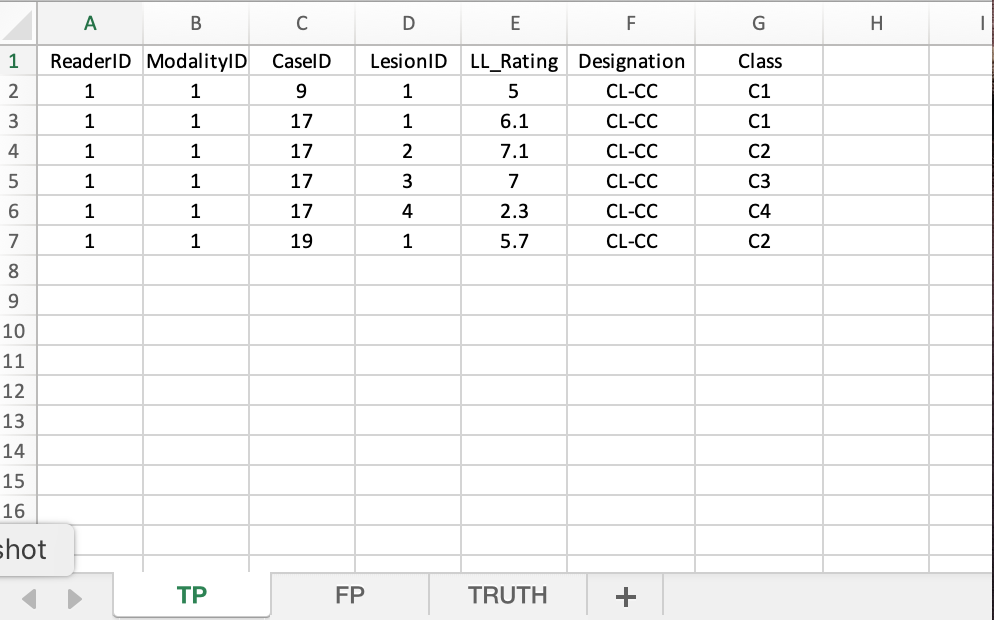
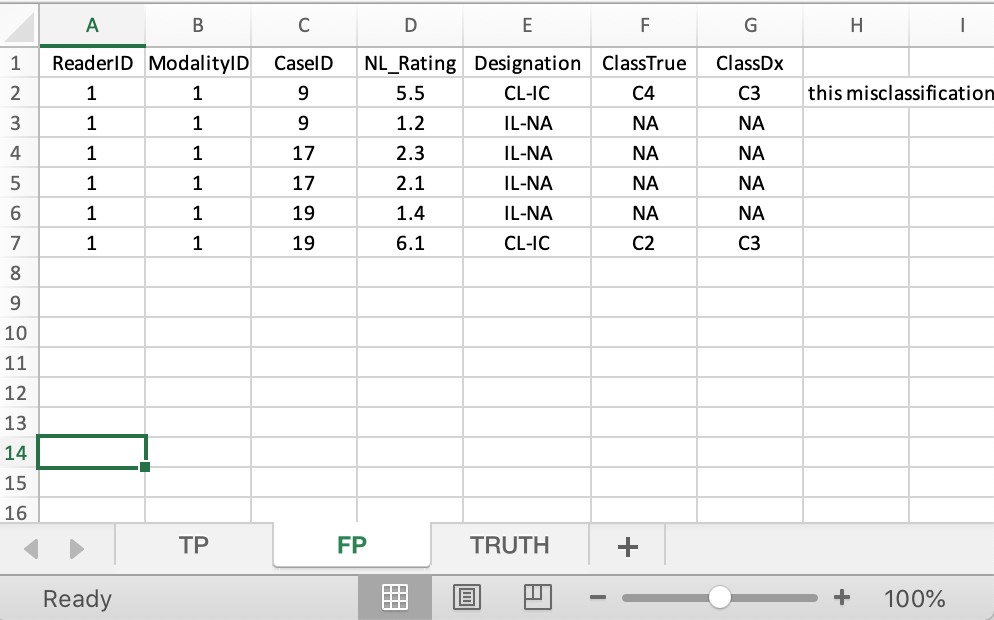
FIGURE 40.5: TP and FP worksheets for File3.xlsx
40.8 Fourth example, File4.xlsx
So far we have dealt with one modality and one reader.
- Additional algorithmic readers can be added under
readerID. - They should not be added as additional treatments (has to do with treatment being regarded as a fixed factor and reader as as random factor in the analysis).
- The starting point is
File3.xlsx. I duplicated the data from this for two additional readers to create a single-modality three-reader datasetFile4.xlsx. - Shown next are the three worksheets.
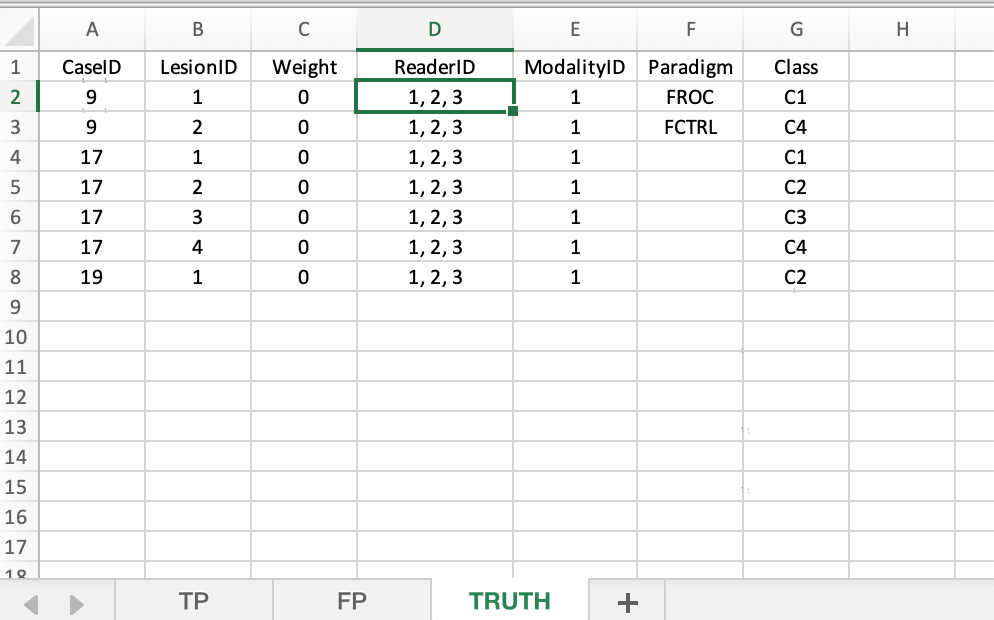
FIGURE 40.6: Truth worksheet for File4.xlsx
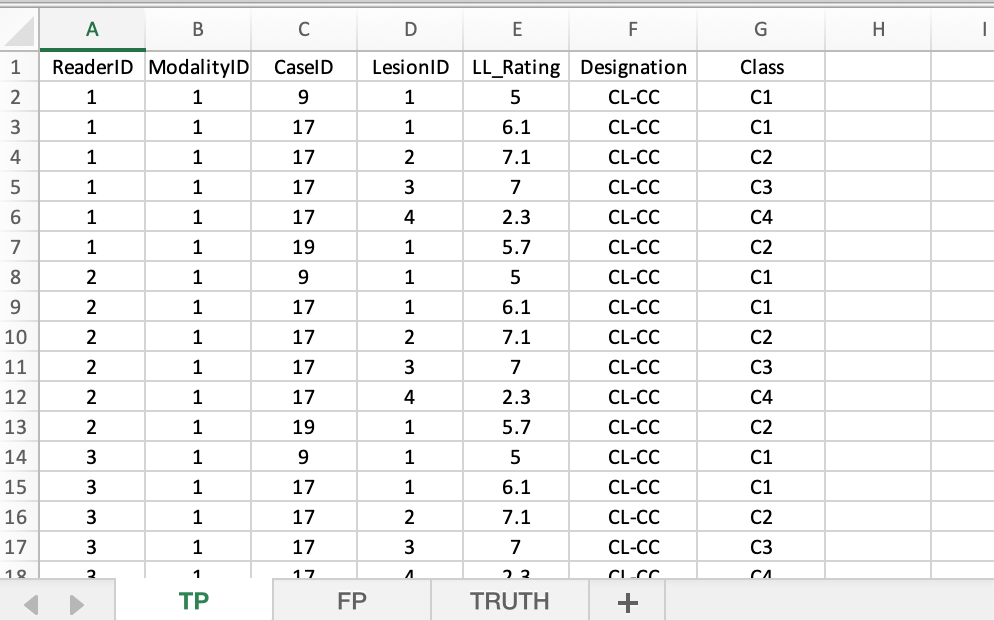
FIGURE 40.7: TP worksheet for File4.xlsx
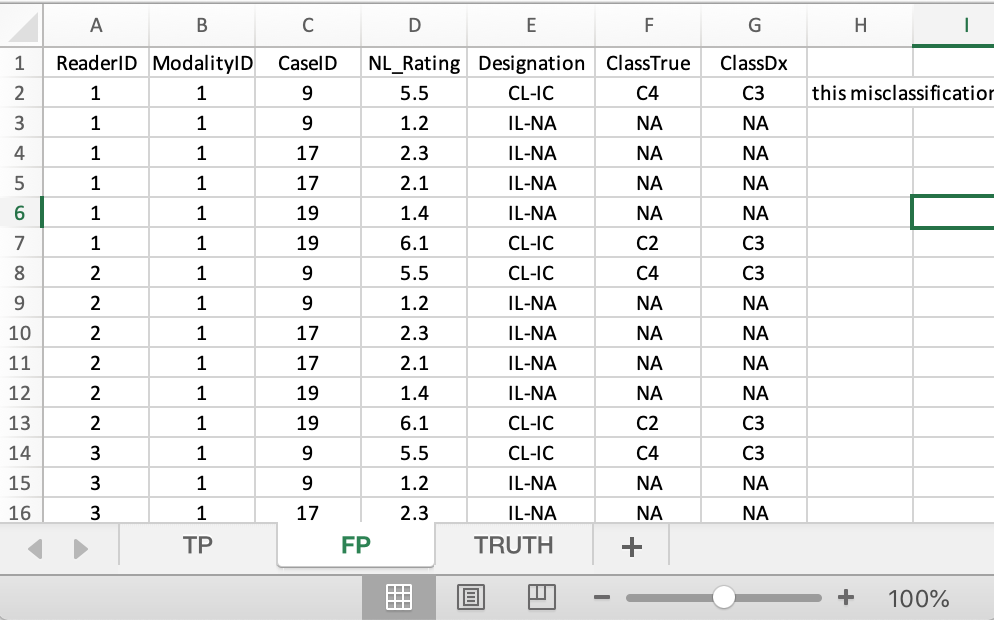
FIGURE 40.8: FP worksheet for File4.xlsx
- Shown next are the three FOMs. Note that they are identical.
40.9 Fifth example, File5.xlsx
- Need to add some randomness to the ratings.
- I randomly added to the ratings from a uniform distribution in the range -0.5 to +0.5.
- This is very crude, as in practice the the number of marks will also vary from reader to reader.
- But file
File5.xlsxshould give one the general idea of how to extend to several algorithmic readers. - Note that now the FOMs are not identical.
40.10 Precautions
- Unlike regular
RJafrocanalysis, there is no error checking of the classification codesC1, etc. For example, if a lesion with classC1is recorded in the TP sheet as a CL-CC and it is also mistakenly recorded in the FP sheet as a CL-IC, the program does not know about the mistake. Multiple FP on the same case are allowed in FROC analysis. - I suggest that the extra columns in the sample files be recorded for your dataset. This will enable me to subsequently include error-checking code for data entry mistakes.
- For example, the columns
Designation,ClassTrueandClassRxin theFPsheet are currently not read by the software. - To make further progress you need to drastically reduce the file size (once the new method is fully developed you can always add the remaining cases and readers). The current file size makes it impossible to fully develop the system. Most studies in this field are done with 2-3 modalities and about 100-200 cases.