Chapter 10 Three proper ROC fits
10.2 TBA Introduction
A proper ROC curve is one whose slope decreases monotonically as the operating point moves up the curve, a consequence of which is that a proper ROC does not display an inappropriate chance line crossing followed by a sharp upward turn, i.e., a “hook”, usually near the (1,1) upper right corner.
There are three methods for fitting proper curves to ROC datasets:
- The radiological search model (RSM) described in Chapter 9,
- The PROPROC (proper ROC) model described in TBA Chapter 20.
- The CBM (contaminated binormal model) described in TBA Chapter 20.
This chapter compares these methods by fitting them to 14 multiple-treatment multiple-reader datasets described in Chapter 14. 33
The motivation for this work was a serendipitous finding (DP Chakraborty and Svahn 2011) that PROPROC fitted ROC AUCs and RSM fitted ROC AUCs were identical for some datasets. This led to extending that work to include CBM and more datasets.
10.3 Application to datasets
Both RSM and CBM are implemented in RJafroc. PROPROC is implemented in Windows software OR DBM-MRMC 2.5 34 that was available here, last accessed 1/4/21.
The RSM, PROPROC and CBM algorithms were applied to datasets described in Chapter 14.
datasetNames <-
c("TONY", "VD", "FR",
"FED", "JT", "MAG",
"OPT", "PEN", "NICO",
"RUS", "DOB1", "DOB2",
"DOB3", "FZR")These are abbreviations for “TONY”, “Van Dyke”, “Franken”, “Federica”, “Thompson”, “Magnus”, “Lucy Warren”, “Penedo”, “Nico-CAD-ROC”, “Ruschin”, “Dobbins-1”, “Dobbins-2”, “Dobbins-3”, “Federica Real Roc”. These datasets are included with RJafroc and the corresponding objects are named datasetXX, where XX is an integer ranging from 1 to 14.
In the following we focus, for now, on just two ROC datasets (these have been widely used in the literature to illustrate ROC analysis methodology advances) namely the Van Dyke (VD) and the Franken (FR) datasets. Illustrative examples are shown for treatment 1 and reader 2 for the Van Dyke dataset and for treatment 2 and reader 3 for the Franken dataset. Plots for all treatment-reader combinations for these two datasets are in Appendix 10.10.3 and Appendix 10.10.4.
# VD dataset
ret <- Compare3ProperRocFits(datasetNames, which(datasetNames == "VD"))
resultsVD <- ret$allResults
plotsVD <- ret$allPlots
# FR dataset
ret <- Compare3ProperRocFits(datasetNames, which(datasetNames == "FR"))
resultsFR <- ret$allResults
plotsFR <- ret$allPlots- The supporting code is in the function
Compare3ProperRocFits()located atR/compare-3-fits/Compare3ProperRocFits.R. - The analyzed results file locations are shown in Section 10.10.2.
- The fitted parameters are contained in
resultsVDandresultsFR; the composite plots (i.e., 3 overlaid plots corresponding to the three proper ROC fitting algorithms) for each treatment and reader, are contained inplotsVDandplotsFR`.
10.4 Composite plots
- The
plotArrlist contains plots for the two datasets. The Van Dyke plots are inplotsVDand the Franken inplotsFR. - The Van Dyke dataset contains \(I \times J = 2 \times 5 = 10\) composite plots.
- The Franken dataset contains \(I \times J = 2 \times 4 = 8\) composite plots.
The following code shows how to display the composite plot for the Van Dyke dataset for treatment 1 and reader 2, i.e., i = 1 and j = 2.
plotsVD[[1,2]]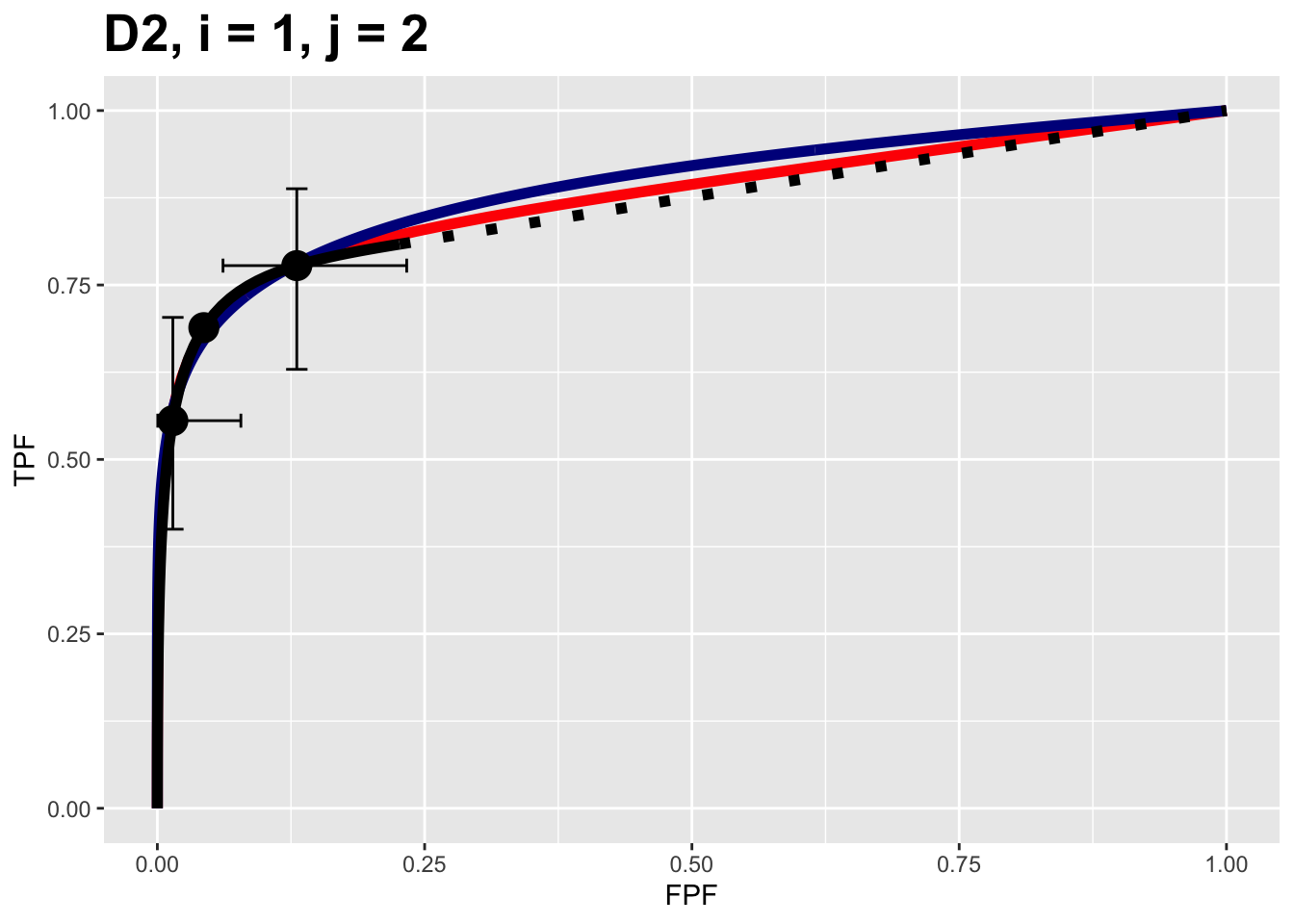
FIGURE 10.1: Composite plots for Van Dyke dataset for treatment = 1, reader 2.
It contains 3 fitted curves:
- The RSM fitted curve is in black.
- The PROPROC fitted curve is in red.
- The CBM fitted curve is in blue.
Three operating points from the binned data are shown as well as exact 95% confidence intervals for the lowest and uppermost operating points.
All 10 composite plots for the Van Dyke dataset are shown in Appendix 10.10.3.
The next example shows composite plots for the Franken dataset for treatment = 2 and reader = 3.
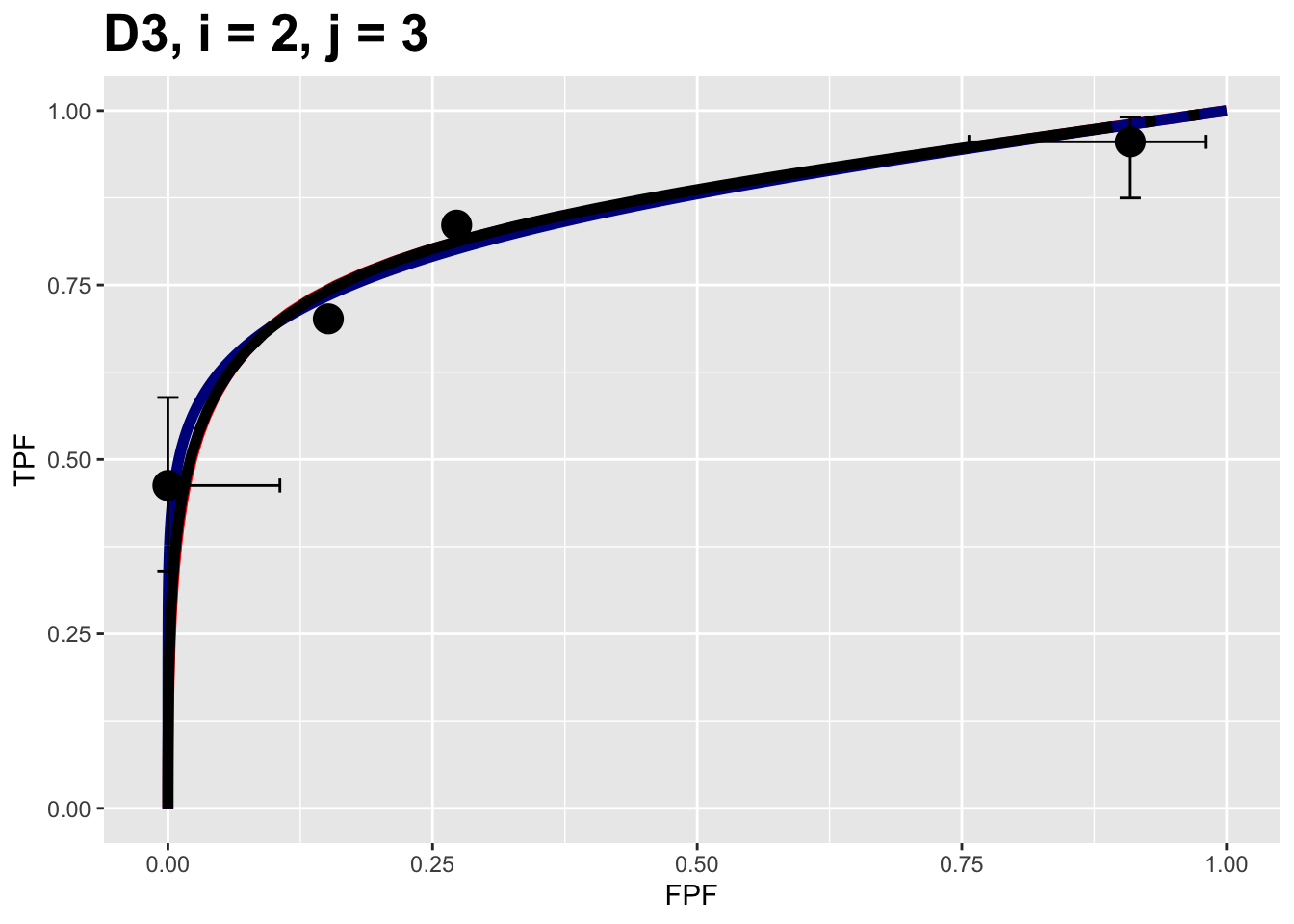
FIGURE 10.2: Composite plots for Franken dataset for treatment = 2, reader 3.
Note that the RSM end-point is almost at the upper right corner, implying lower lesion-localization performance.
All 10 composite plots for the Franken dataset are shown in Appendix 10.10.4.
10.5 RSM parameters
The parameters corresponding to the RSM plots for the Van Dyke dataset are accessed as shown next.
resultsVD[[i,j]]$retRsm$muis the RSM \(\mu\) parameter for the Van Dyke dataset for treatment i and reader j;resultsVD[[i,j]]$retRsm$lambdais the RSM \(\lambda\) parameter;
resultsVD[[i,j]]$retRsm$nuis the RSM \(\nu\) parameter;resultsVD[[i,j]]$retRsm$zeta1is the RSM \(\zeta_1\) parameter;
10.5.1 RSM parameters Van Dyke dataset i = 1, j= 2
The following displays RSM parameters for the Van Dyke dataset, treatment 1 and reader 2:
## RSM parameters, Van Dyke Dataset, i=1, j=2:
## mu = 2.201413
## lambda = 0.2569453
## nu = 0.7524016
## zeta_1 = -0.1097901
## AUC = 0.8653694
## sigma_AUC = 0.04740562
## NLLini = 96.48516
## NLLfin = 85.86244The first four values are the fitted values for the RSM parameters \(\mu\), \(\lambda\), \(\nu\) and \(\zeta_1\). The next value is the AUC under the fitted RSM curve followed by its standard error. The last two values are the initial and final values of negative log-likelihood 35.
From the previous chapter the RSM parameters can be used to calculate lesion-localization and lesion-classification performances, namely \(L_L\) and \(L_C\) respectively. The following function calculates these values:
LesionLocLesionCls <- function(mu, lambda, nu, lesDistr) {
temp <- 0
for (L in 1:length(lesDistr)) {
temp <- temp + lesDistr[L] * (1 - nu)^L
}
L_L <- exp(-lambda) * (1 - temp)
L_C <- pnorm(mu/sqrt(2))
return(list(
L_L = L_L,
L_C = L_C
))
}The function is used as follows:
mu <- resultsVD[[1,2]]$retRsm$mu
lambda <- resultsVD[[1,2]]$retRsm$lambda
nu <- resultsVD[[1,2]]$retRsm$nu
f <- which(datasetNames == "VD")
fileName <- datasetNames[f]
theData <- get(sprintf("dataset%02d", f)) # the datasets already exist as R objects
lesDistr <- UtilLesionDistrVector(theData) # RSM ROC fitting needs to know lesDistr
ret <- LesionLocLesionCls(mu, lambda, nu, lesDistr)
L_L <- ret$L_L
L_C <- ret$L_C
cat(sprintf("VD data i=1 j=2: L_L = %7.3f, L_C = %7.3f", L_L, L_C), "\n")## VD data i=1 j=2: L_L = 0.582, L_C = 0.94010.5.2 RSM parameters Franken dataset i = 2, j= 3
For the Franken dataset the values are accessed as resultsFR[[i,j]].
Displayed next are RSM parameters for the Franken dataset, treatment 2 and reader 3:
## RSM parameters, Franken dataset, i=2, j=3:
## mu = 2.641412
## lambda = 2.137379
## nu = 0.784759
## zeta_1 = -1.858565
## AUC = 0.8552573
## sigma_AUC = 0.03809136
## NLLini = 132.6265
## NLLfin = 127.9418Shown next are the lesion-localization and lesion-classification performances for this dataset.
## FR data i=2, j=3: L_L = 0.093, L_C = 0.969While the lesion-classification performances are similar for the two examples, the lesion-localization performances are different, with the Van Dyke dataset showing a greater value. This is evident from the location of the end-points in the two plots shown in Fig. 10.1 and Fig. 10.2 (an end-point closer to the top-left corner implies greater lesion-localization performance).
10.6 CBM parameters
The parameters of the CBM plots are accessed as shown next.
results[[i,j]]$retCbm$muis the CBM \(\mu\) parameter for treatment i and reader j;results[[i,j]]$retCbm$alphais the CBM \(\alpha\) parameter;
as.numeric(results[[i,j]]$retCbm$zetas[1])is the CBM \(\zeta_1\) parameter, the threshold corresponding to the highest non-trivial operating point;results[[i,j]]$retCbm$AUCis the CBM AUC;as.numeric(results[[i,j]]$retCbm$StdAUC)is the standard deviation of the CBM AUC;results[[i,j]]$retCbm$NLLIniis the initial negative log-likelihood value;results[[i,j]]$retCbm$NLLFin)is the final negative log-likelihood value.
The next example displays CBM parameters and AUC etc. for the Van Dyke dataset, treatment 1 and reader 2:
## CBM parameters, Van Dyke Dataset, i=1, j=2:
## mu = 2.745791
## alpha = 0.7931264
## zeta_1 = 1.125028
## AUC = 0.8758668
## sigma_AUC = 0.03964492
## NLLini = 86.23289
## NLLfin = 85.88459The next example displays CBM parameters for the Franken dataset, treatment 2 and reader 3:
## CBM parameters, Franken dataset, i=2, j=3:
## mu = 2.324116
## alpha = 0.8796571
## zeta_1 = -0.5599662
## AUC = 0.8957135
## sigma_AUC = 0.03223745
## NLLini = 98.30823
## NLLfin = 97.82786The first three values are the fitted values for the CBM parameters \(\mu\), \(\alpha\) and \(\zeta_1\). The next value is the AUC under the fitted CBM curve followed by its standard error. The last two values are the initial and final values of negative log-likelihood.
10.7 PROPROC parameters
For the VD dataet the PROPROC displayed parameters are accessed as follows:
resultsVD[[i,j]]$c1is the PROPROC \(c\) parameter for treatment i and reader j;resultsVD[[i,j]]$dais the PROPROC \(d_a\) parameter;
resultsVD[[i,j]]$aucPropis the PROPROC AUC;
Other statistics, such as standard error of AUC, are not provided by PROPROC software.
The next example displays PROPROC parameters for the Van Dyke dataset, treatment 1 and reader 2:
## PROPROC parameters, Van Dyke Dataset, i=1, j=2:
## c = -0.2809004
## d_a = 1.731472
## AUC = 0.8910714The values are identical to those listed for treatment 1 and reader 2 in Fig. 10.8.
The next example displays PROPROC parameters for the Franken dataset, treatment 2 and reader 3:
## PROPROC parameters, Franken dataset, i=2, j=3:
## c = -0.3299822
## d_a = 2.078543
## AUC = 0.9304317The next section provides an overview of the most salient findings from analyzing the datasets.
10.8 Overview of findings
With 14 datasets the total number of individual modality-reader combinations is 236: in other words, there are 236 datasets to each of which the three fitting algorithms were applied.
It is easy to be overwhelmed by the numbers so this section summarizes an important conclusion: The three fitting algorithms are consistent with a single algorithm-independent AUC.
If the AUCs of the three methods are identical the following relations hold with each slope \(\text{m}_{PR}\) and \(\text{m}_{CR}\) equal to unity:
\[\begin{equation} \left. \begin{aligned} \text{AUC}_{\text{PRO}} =& \text{m}_{PR} \text{AUC}_{\text{PRO}} \\ \text{AUC}_{\text{CBM}} =& \text{m}_{CR} \text{AUC}_{\text{PRO}} \end{aligned} \right \} \tag{10.1} \end{equation}\]
The abbreviations are as follows:
- PRO = PROPROC
- PR = PROPROC vs. RSM
- CR = CBM vs. RSM.
For each dataset the plot of PROPROC AUC vs. RSM AUC should be linear with zero intercept and slope \(\text{m}_{PR}\), and likewise for the plots of CBM AUC vs. RSM AUC. The reason for the zero intercept is that if the AUCs are identical one cannot have an offset (i.e., intercept) term.
10.8.1 Slopes
Denote PROPROC AUC for dataset \(f\), where \(f=1,2,...,14\), treatment \(i\) and reader \(j\) by \(\text{AUC}^{\text{PRO}}_{fij}\). Likewise, the corresponding RSM and CBM values are denoted by \(\text{AUC}^{\text{RSM}}_{fij}\) and \(\text{AUC}^{\text{CBM}}_{fij}\), respectively.
For a given dataset the slope of the PROPROC values vs. the RSM values is denoted \(\text{m}_{\text{PR},f}\).
The (grand) average over all datasets is denoted \(\text{m}^{\text{PR}}_\bullet\). Likewise, the (grand) average of the CBM AUC vs. the RSM slopes is denoted \(\text{m}^{\text{CR}}_\bullet\).
An analysis was conducted to determine the average slopes and bootstrap confidence intervals.
The code for calculating the average slopes is in R/compare-3-fits/slopesConvVsRsm.R and that for the bootstrap confidence intervals is in R/compare-3-fits/slopesAucsConvVsRsmCI.R.
slopes <- slopesConvVsRsm(datasetNames)
slopeCI <- slopesAucsConvVsRsmCI(datasetNames)The call to function slopesConvVsRsm() returns slopes, which contains, for each of 14 datasets, four lists: two plots and two slopes. For example:
- PRO vs. RSM:
slopes$p1[[2]]is the plot of \(\text{AUC}^{\text{PRO}}_{2 \bullet \bullet}\) vs. \(\text{AUC}^{RSM}_{2 \bullet \bullet}\) for all treatments and readers in the Van Dyke dataset. The plot for dataset \(f, f = 1, 2, ...14\) is accessed asslopes$p1[[f]]which yields the plot of \(\text{AUC}^{\text{PRO}}_{f \bullet \bullet}\) vs. \(\text{AUC}^{RSM}_{f \bullet \bullet}\). - CBM vs. RSM:
slopes$p2[[2]]is the plot of \(\text{AUC}^{\text{CBM}}_{2 \bullet \bullet}\) vs. \(\text{AUC}^{RSM}_{2 \bullet \bullet}\) for for all treatments and readers in the Van Dyke dataset. The plot for dataset \(f\) is accessed asslopes$p2[[f]]. - PRO vs. RSM:
slopes$m_pro_rsmhas two columns, each of length 14, the slopes \(\text{m}_{PR,f}\) for the datasets (indexed by \(f\)) and the corresponding \(R^2\) values, where \(R^2\) is the fraction of variance explained by the zero-intercept straight line fit. The first column isslopes$m_pro_rsm[[1]]and the second column isslopes$m_pro_rsm[[2]]. - CBM vs. RSM:
slopes$m_cbm_rsmhas two columns, each of length 14, the slopes \(\text{m}_{CR,f}\) for the datasets and the corresponding \(R^2\) values. The first column isslopes$m_cbm_rsm[[1]]and the second column isslopes$m_cbm_rsm[[2]].
As an example, for the Van Dyke dataset, slopes$p1[[2]] which is shown in the left in Fig. 10.3, is the plot of \(\text{AUC}^{\text{PRO}}_{2 \bullet \bullet}\) vs. \(\text{AUC}^{RSM}_{2 \bullet \bullet}\). Shown in the right is slopes$p2[[2]], the plot of \(\text{AUC}^{\text{CBM}}_{2 \bullet \bullet}\) vs. \(\text{AUC}^{RSM}_{2 \bullet \bullet}\). Each plot has the zero-intercept linear fit superposed on the \(2\times5 = 10\) data points; each data point represents a distinct modality-reader combination.
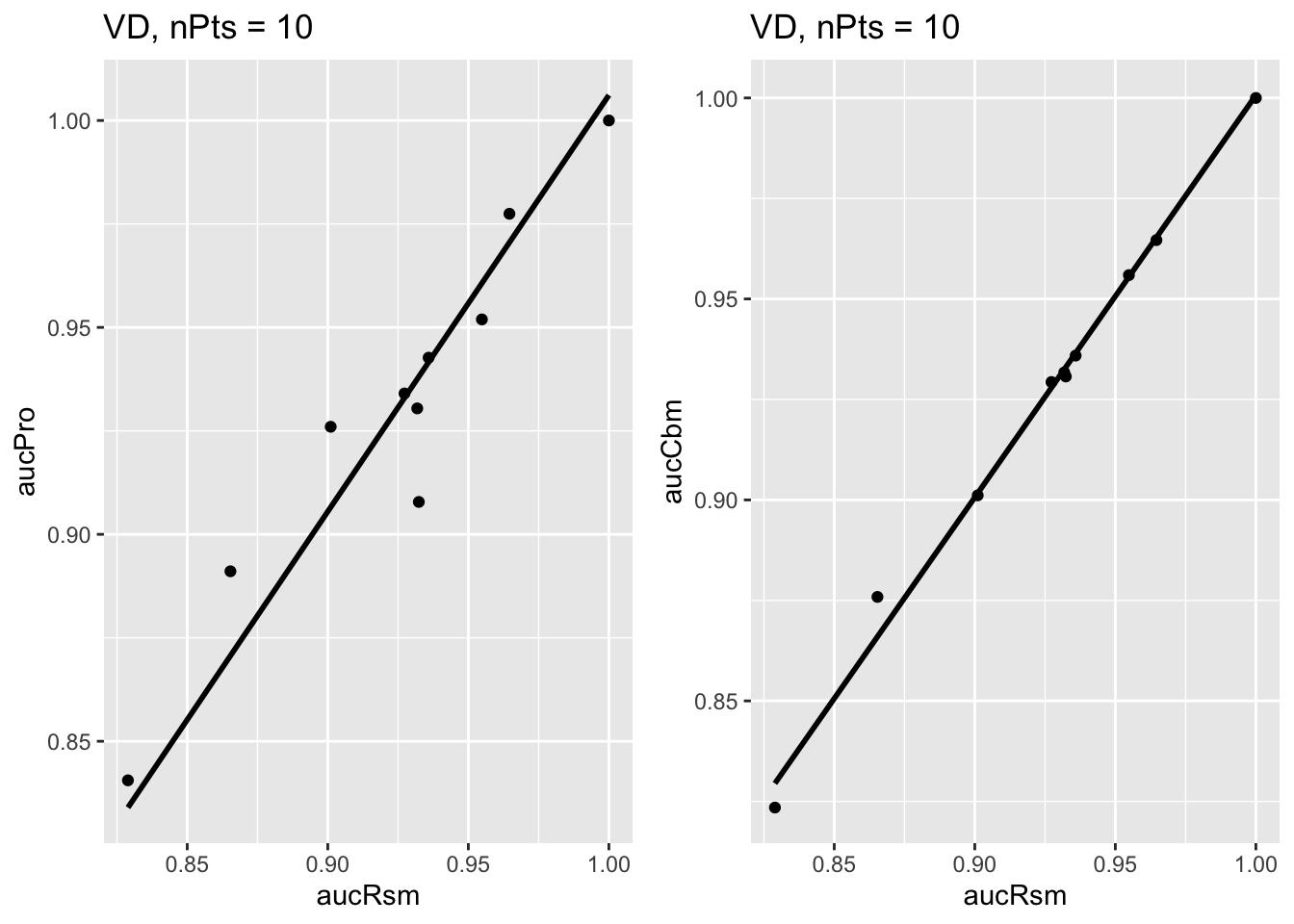
FIGURE 10.3: Van Dyke dataset: Left plot is PROPROC-AUC vs. RSM-AUC with the superposed zero-intercept linear fit. The number of data points is nPts = 10. Right plot is CBM-AUC vs. RSM-AUC.
The next plot shows corresponding plots for the Franken dataset in which there are \(2\times 4 = 8\) points in each plot.
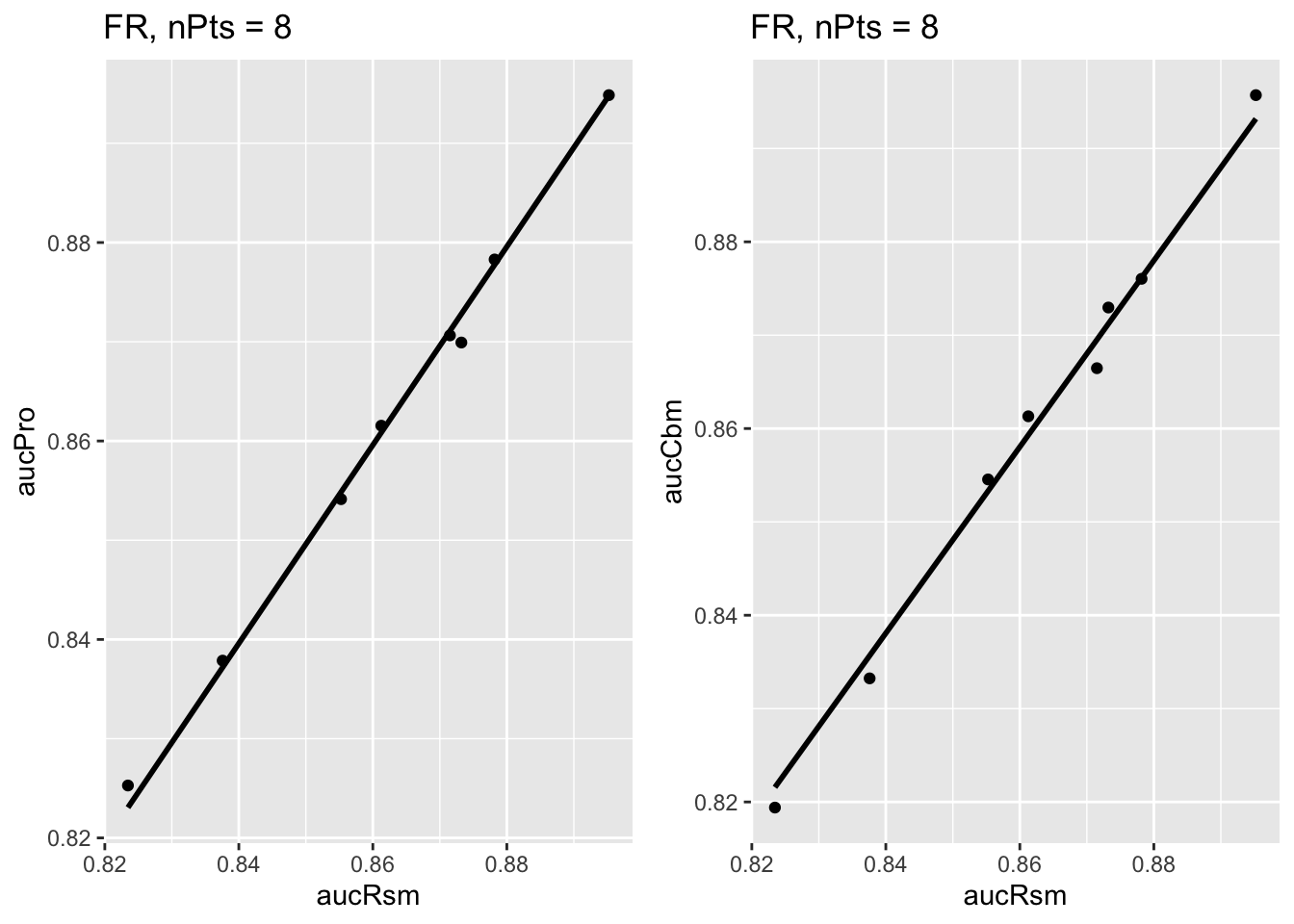
FIGURE 10.4: Similar to previous plot, for Franken dataset.
10.8.2 Confidence intervals
The call to slopesAucsConvVsRsmCI returns slopeCI, containing the results of the bootstrap analysis (the bullet symbols \(\bullet\) denote grand averages over 14 datasets):
slopeCI$cislopeProRsm95-percent confidence interval for \(\text{m}_{\text{PR} \bullet}\)slopeCI$cislopeCbmRsm95-percent confidence interval for \(\text{m}_{\text{CR} \bullet}\)slopeCI$histSlopeProRsmhistogram of 200 bootstrap values of \(\text{m}_{\text{PR} \bullet}\)slopeCI$histSlopeCbmRsmhistogram of 200 bootstrap values of \(\text{m}_{\text{CR} \bullet}\)slopeCI$ciAvgAucRsmconfidence interval from 200 bootstrap values of \(\text{AUC}^{\text{RSM}}_\bullet\)slopeCI$ciAvgAucProconfidence interval for 200 bootstrap values of \(\text{AUC}^{\text{PRO}}_\bullet\)slopeCI$ciAvgAucCbmconfidence interval for 200 bootstrap values of \(\text{AUC}^{\text{CBM}}_\bullet\)
As examples,
## m-PR m-CR
## 2.5% 1.005092 0.9919886
## 97.5% 1.012285 0.9966149The CI for \(\text{m}_{\text{PR} \bullet}\) is slightly above unity, while that for \(\text{m}_{\text{CR} \bullet}\) is slightly below. Shown next is the histogram plot for \(\text{m}_{\text{PR} \bullet}\) (left plot) and \(\text{m}_{\text{CR} \bullet}\) (right plot). Quantiles of these histograms were used to compute the previously cited confidence intervals.
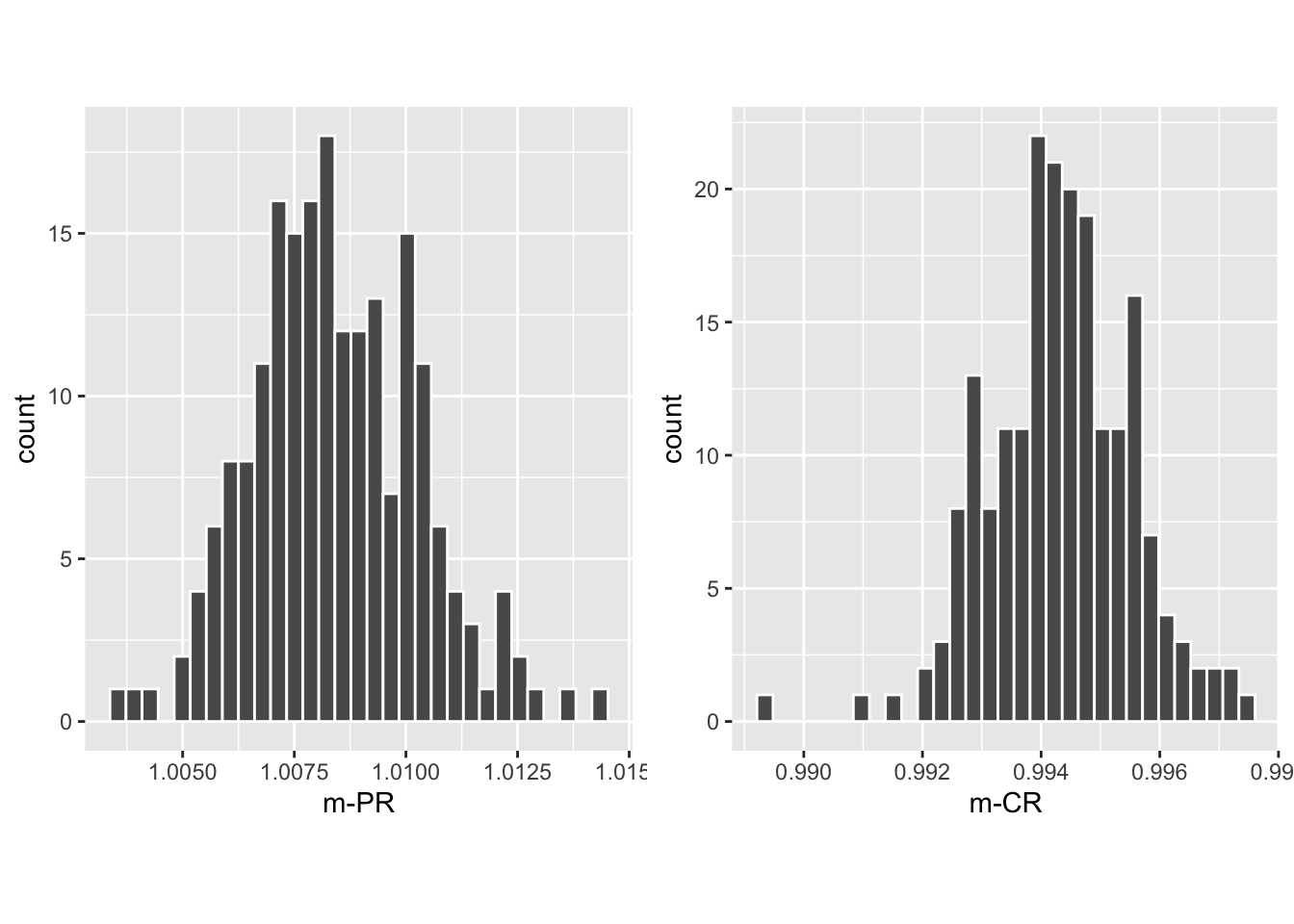
FIGURE 10.5: Histograms of slope PROPROC AUC vs. RSM AUC (left) and slope CBM AUC vs. RSM AUC (right).
10.8.3 Summary of slopes and confidence intervals
| \(\text{m}_{PR}\) | \(R^2_{PR}\) | \(\text{m}_{CR}\) | \(R^2_{CR}\) | |
|---|---|---|---|---|
| TONY | 1.0002 | 0.9997 | 0.9933 | 0.9997 |
| VD | 1.0061 | 0.9998 | 1.0007 | 1 |
| FR | 0.9995 | 1 | 0.9977 | 1 |
| FED | 1.0146 | 0.9998 | 0.9999 | 0.9999 |
| JT | 0.9964 | 0.9995 | 0.9972 | 1 |
| MAG | 1.036 | 0.9983 | 0.9953 | 1 |
| OPT | 1.0184 | 0.9997 | 1.0059 | 0.9997 |
| PEN | 1.0081 | 0.9996 | 0.9976 | 1 |
| NICO | 0.9843 | 0.9998 | 0.997 | 1 |
| RUS | 0.9989 | 0.9999 | 0.9921 | 0.9999 |
| DOB1 | 1.0262 | 0.9963 | 0.9886 | 0.9962 |
| DOB2 | 1.0056 | 0.9987 | 0.971 | 0.9978 |
| DOB3 | 1.0211 | 0.998 | 0.9847 | 0.9986 |
| FZR | 1.0027 | 0.9999 | 0.9996 | 1 |
| AVG | 1.0084 | 0.9992 | 0.9943 | 0.9994 |
| CI | (1.005, 1.012) | NA | (0.992, 0.997) | NA |
In Table 10.1 the second column, labeled \(\text{m}_{PR}\), shows slopes of straight lines, zero-intercept to go through the origin, to PROPROC AUC vs. RSM AUC values, for each of the 14 datasets, as labeled in the fits column. The third column, labeled \(R^2_{PR}\), lists the square of the correlation coefficient for each fit. The fourth and fifth columns list the corresponding values for the CBM AUC vs. RSM AUC fits. The second last row lists the grand averages (AVG) and the last row lists the 95 percent confidence intervals.
10.9 Reason for equal AUCs / Summary
We find that all three proper ROC methods yield almost the same AUC. The reason is that the proper ROC is a consequence of using a decision variable that is equivalent (in the arbitrary monotonic increasing transformations sense, see below) to a likelihood ratio. Proper ROC fitting is discussed in RJafrocRocBook. The likelihood ratio \(l(z)\) is defined as the ratio of the diseased pdf to the non-diseased pdf:
\[\begin{equation} l(z) \equiv \frac{\text{pdf}_D(z)}{\text{pdf}_N(z)} \tag{10.2} \end{equation}\]
There is a theorem (Barrett and Myers 2013) that an observer who uses the likelihood ratio \(l(z)\) or any monotone increasing transformation of it as the decision variable, has optimal performance, i.e., maximum ROC-AUC. To use the terminology of (Barrett and Myers 2013) any observer using the likelihood ratio as the decision variable is an ideal observer (Section 13.2.6 ibid). However, different ideal observers must yield the same AUC as otherwise one observer would be “more ideal” than another. Different models of fitting proper ROCs represent different approaches to modeling the decision variable and the likelihood ratio, but while the curves can have different shapes (the slope of the ROC curve at a given point equals the likelihood ratio calculated at that point) their AUCs must agree. This explains the empirical observation of this chapter that RSM, PROPROC and CBM all yield the same AUCs as summarized in Table 10.1.
10.10 Appendices
10.10.1 Location of PROPROC files
For each dataset PROPROC parameters were obtained by running the Windows software with PROPROC selected as the curve-fitting method. The results are saved to files that end with proprocnormareapooled.csv 36 contained in “R/compare-3-fits/MRMCRuns/C/”, where C denotes the name of the dataset (for example, for the Van Dyke dataset, C = “VD”). Examples are shown in the next two screen-shots.
FIGURE 10.6: Screen shot (1 of 2) of R/compare-3-fits/MRMCRuns showing the folders containing the results of PROPROC analysis on 14 datasets.
FIGURE 10.7: Screen shot (2 of 2) of R/compare-3-fits/MRMCRuns/VD showing files containing the results of PROPROC analysis for the Van Dyke dataset.
The contents of R/compare-3-fits/MRMCRuns/VD/VDproprocnormareapooled.csv are shown next, see Fig. 10.8. 37 The PROPROC parameters \(c\) and \(d_a\) are in the last two columns. The column names are T = treatment; R = reader; return-code = undocumented value, area = PROPROC AUC; numCAT = number of ROC bins; adjPMean = undocumented value; c = \(c\) and d_a = \(d_a\), are the PROPROC parameters defined in (Charles E. Metz and Pan 1999).
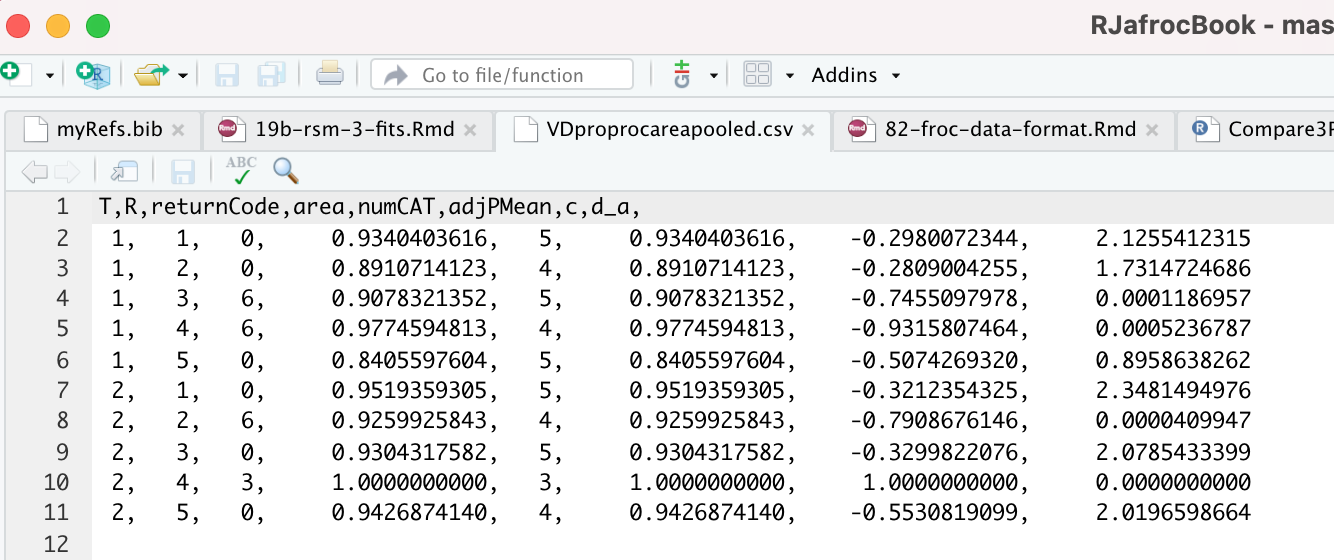
FIGURE 10.8: PROPROC output for the Van Dyke ROC data set. The first column is the treatment, the second is the reader, the fourth is the AUC and the last two columns are the c and \(d_a\) parameters.
10.10.2 Location of pre-analyzed results
The following screen shot shows the pre-analyzed files created by the function Compare3ProperRocFits() described below. Each file is named allResultsC, where C is the abbreviated name of the dataset (uppercase C denotes one or more uppercase characters; for example, C = VD denotes the Van Dyke dataset.).
FIGURE 10.9: Screen shot of R/compare-3-fits/RSM6 showing the results files created by Compare3ProperRocFits().
10.10.3 Plots for the Van Dyke dataset
The following plots are arranged in pairs, with the left plot corresponding to treatment 1 and the right to treatment 2.
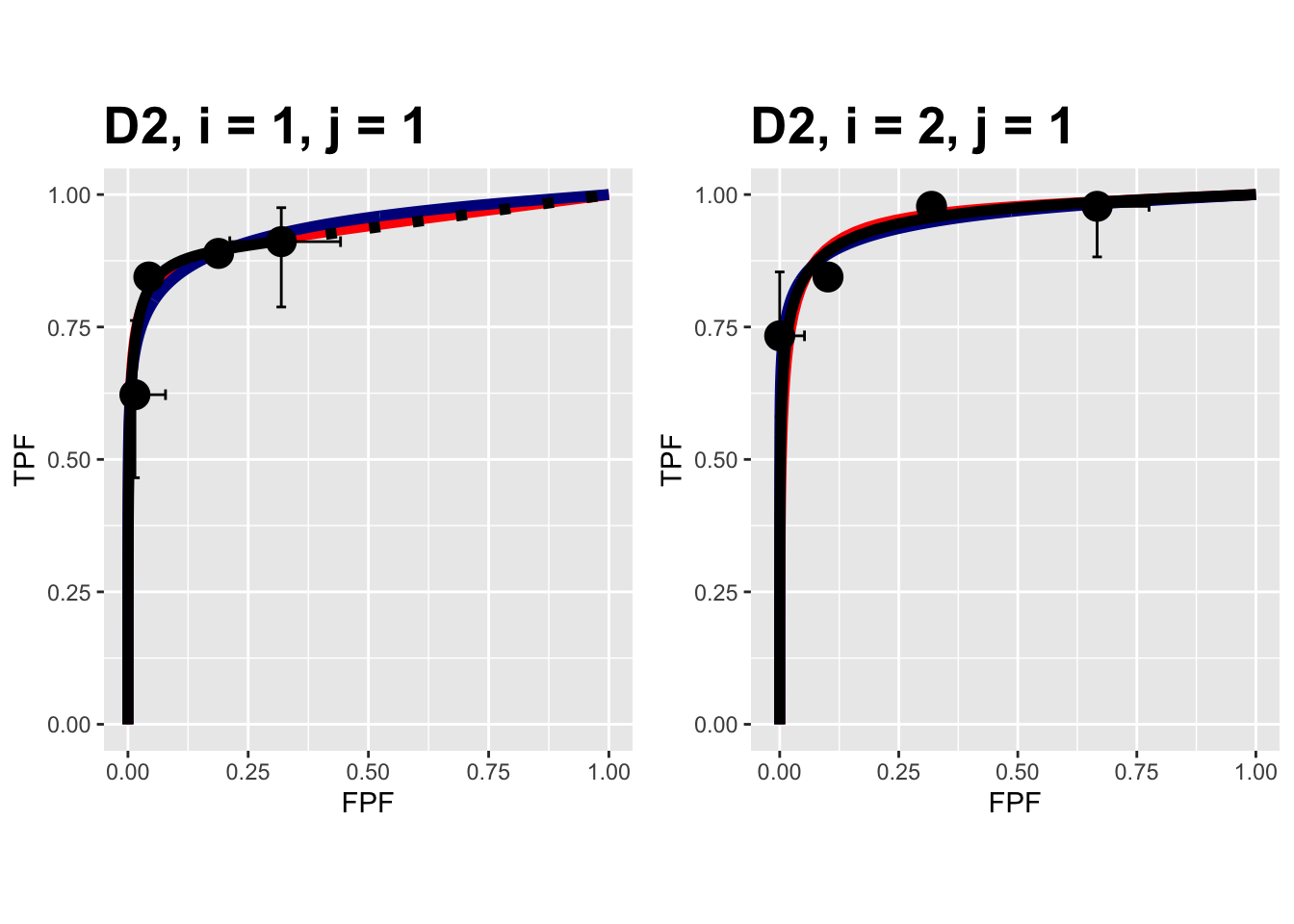
FIGURE 10.10: Composite plots in both treatments for the Van Dyke dataset, reader 1.
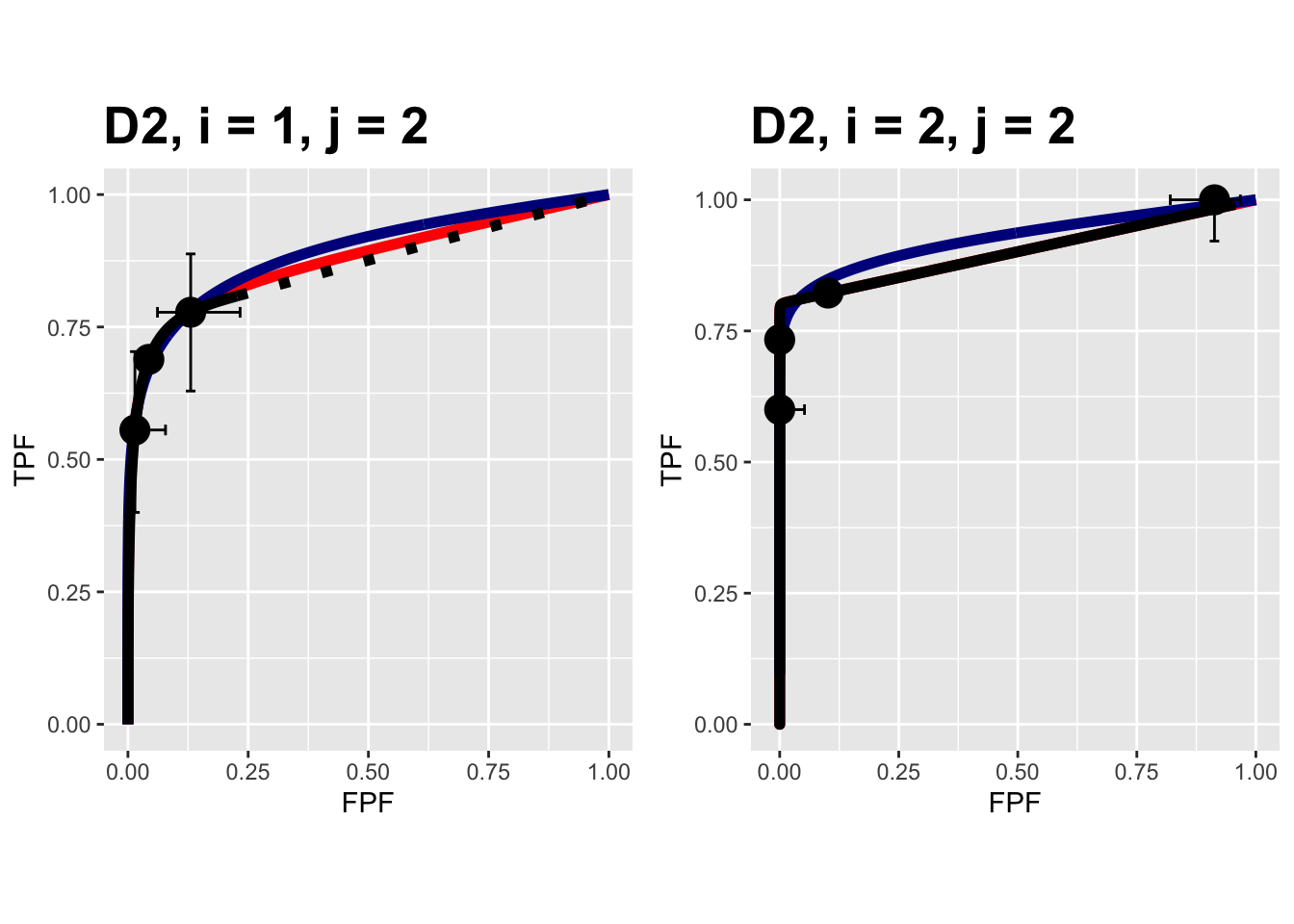
FIGURE 10.11: Composite plots in both treatments for the Van Dyke dataset, reader 2. For treatment 2 the RSM and PROPROC fits are indistinguishable.
The RSM parameter values for the treatment 2 plot are: \(\mu\) = 5.767237, \(\lambda\) = 2.7212621, \(\nu\) = 0.8021718, \(\zeta_1\) = -1.5717303. The corresponding CBM values are \(\mu\) = 5.4464738, \(\alpha\) = 0.8023609, \(\zeta_1\) = -1.4253826. The RSM and CBM \(\mu\) parameters are close and likewise the RSM \(\nu\) and CBM \(\alpha\) parameters are close - this is because they have similar physical meanings, which is investigated later in this chapter TBA. [The CBM does not have a parameter analogous to the RSM \(\lambda\) parameter.]
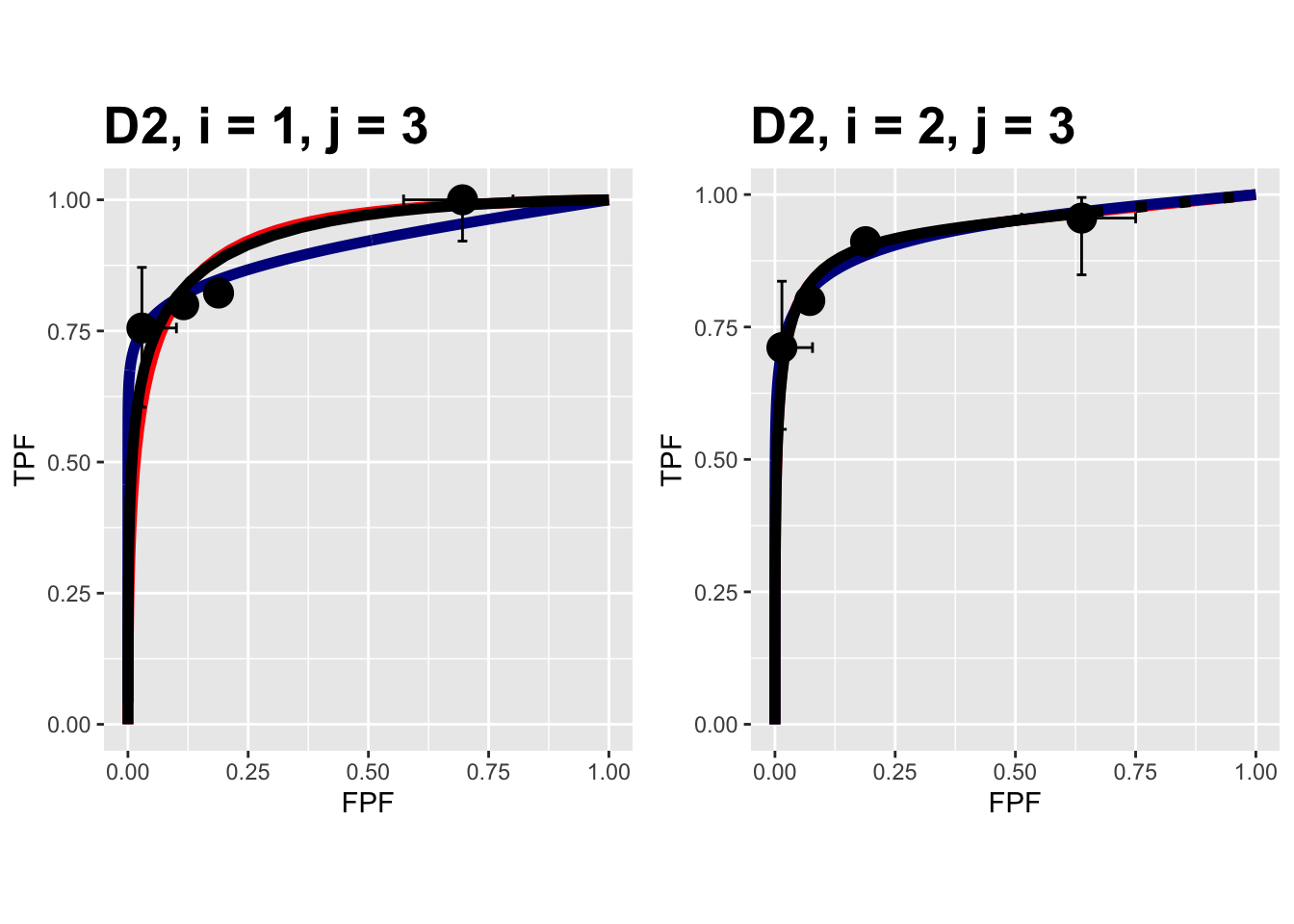
FIGURE 10.12: Composite plots in both treatments for the Van Dyke dataset, reader 3.
The RSM parameters for the treatment 1 plot are: \(\mu\) = 3.1527627, \(\lambda\) = 9.9986154, \(\nu\) = 0.9899933, \(\zeta_1\) = 1.1733988. The corresponding CBM values are \(\mu\) = 2.1927712, \(\alpha\) = 0.98, \(\zeta_1\) = -0.5168848.
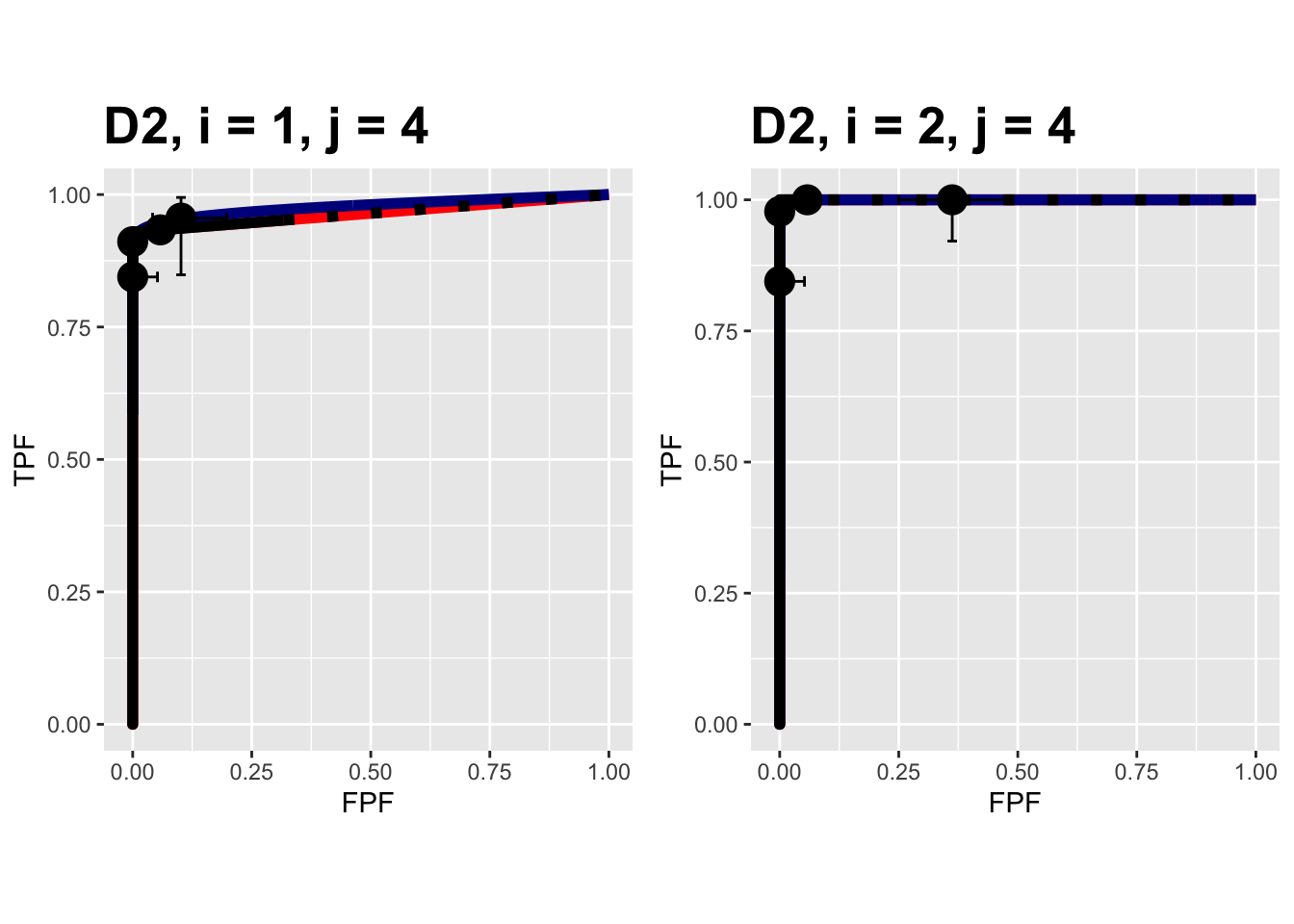
FIGURE 10.13: Composite plots in both treatments for the Van Dyke dataset, reader 4. For treatment 2 the 3 plots are indistinguishable and each one has AUC = 1. The degeneracy is due to all operating points being on the axes of the unit square.
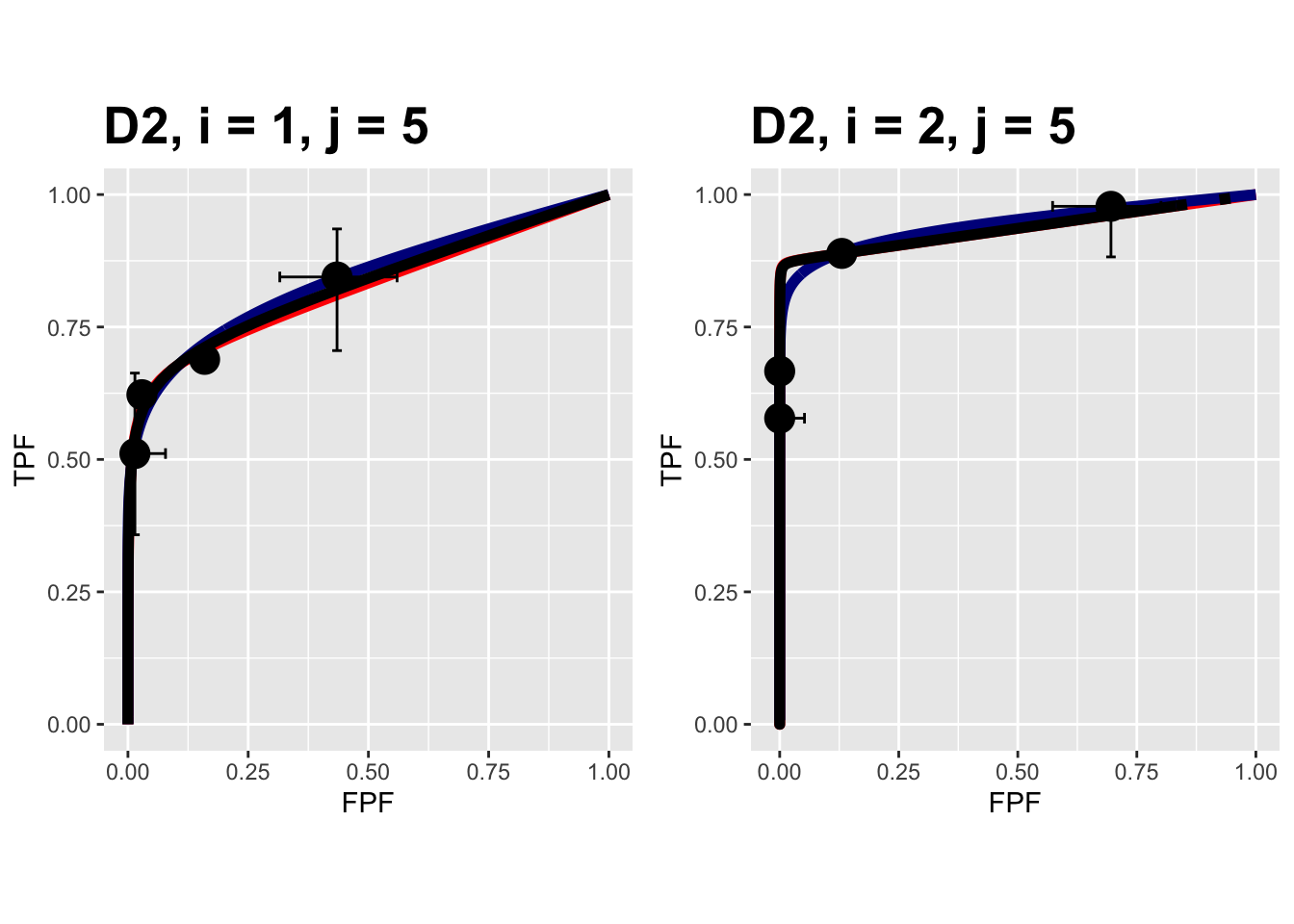
FIGURE 10.14: Composite plots in both treatments for the Van Dyke dataset, reader 5.
10.10.4 Plots for the Franken dataset
The following plots are arranged in pairs, with the left plot corresponding to treatment 1 and the right to treatment 2. These plots apply to the Franken dataset.
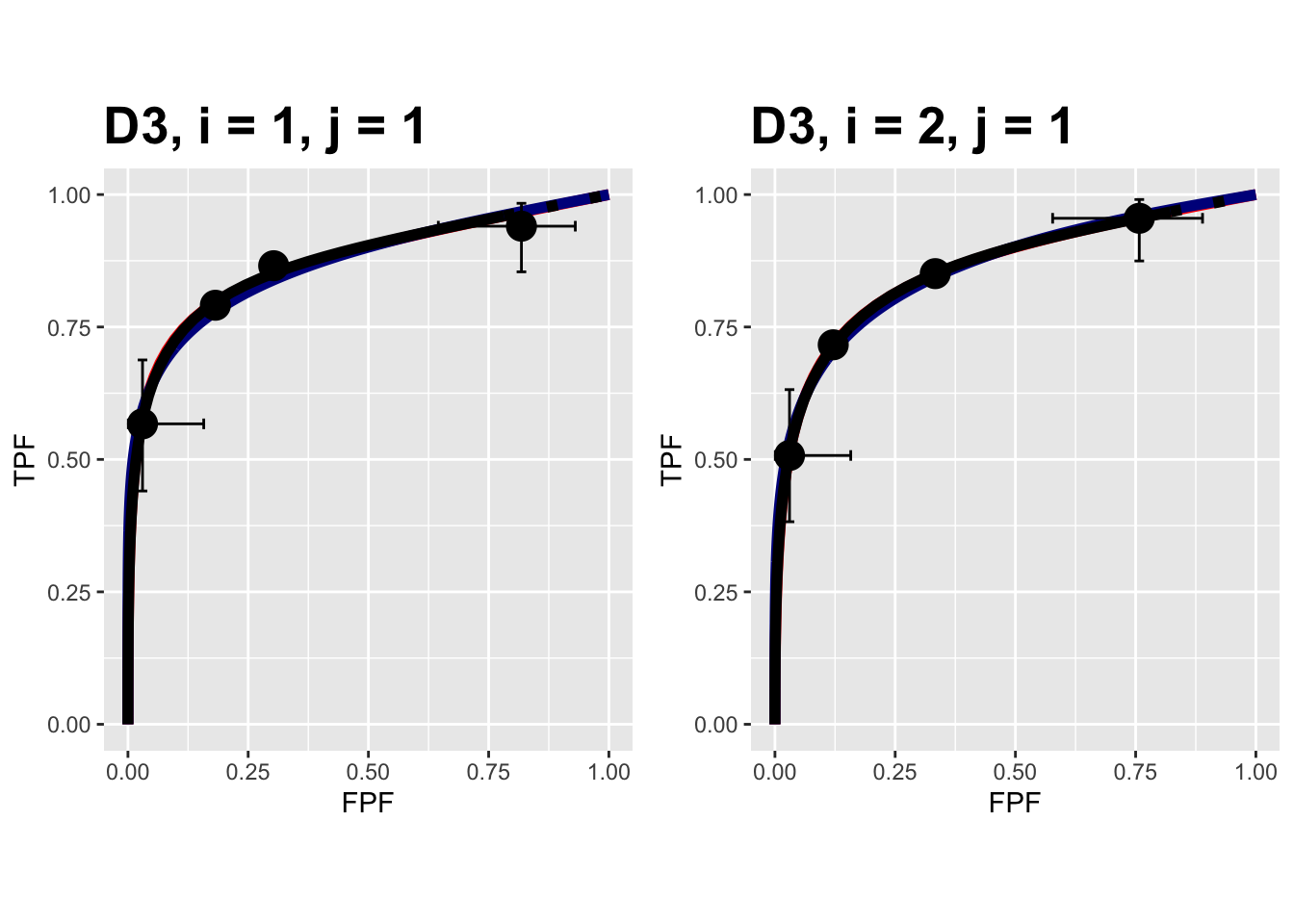
FIGURE 10.15: Composite plots in both treatments for the Franken dataset, reader 1.
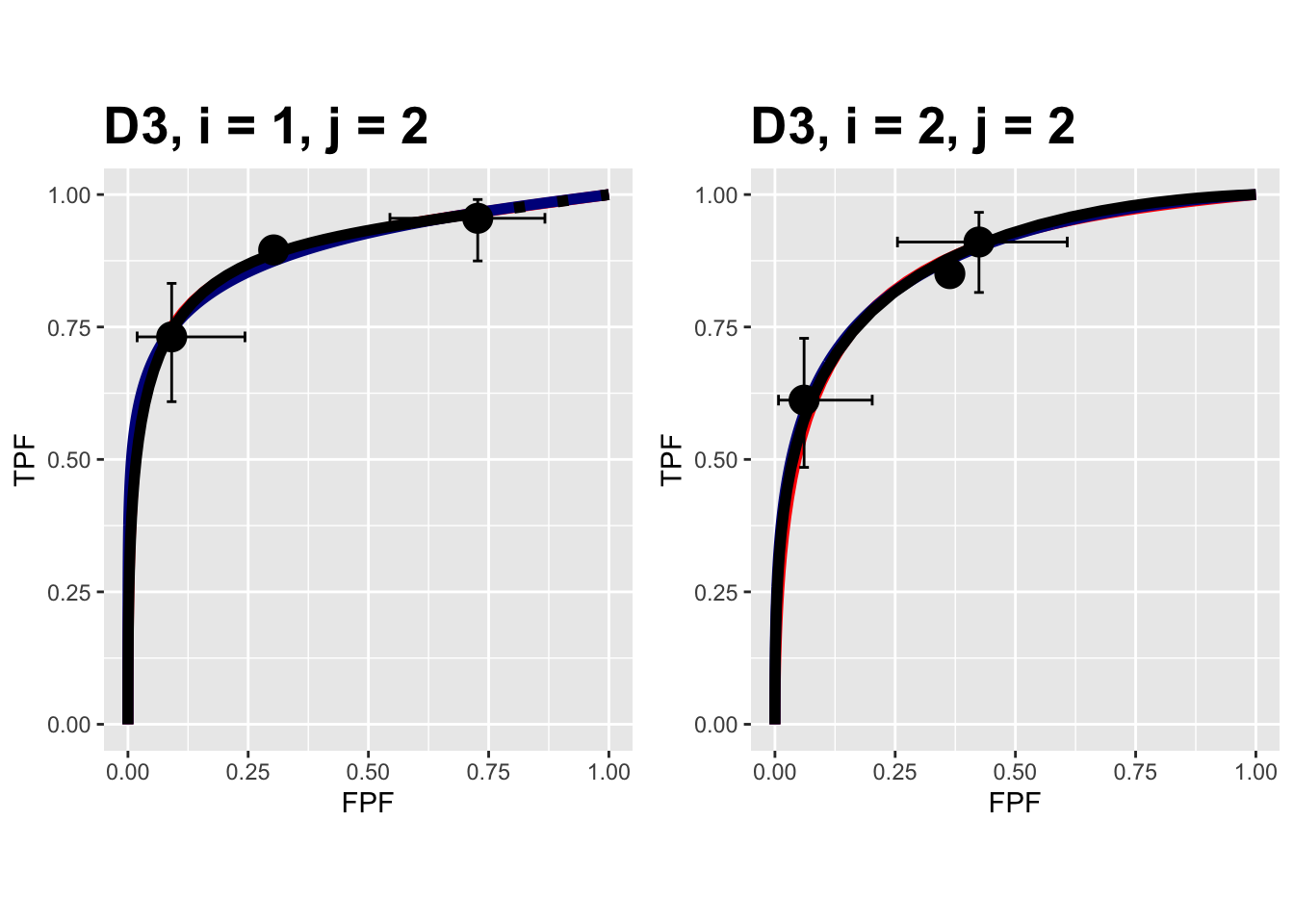
FIGURE 10.16: Composite plots in both treatments for the Franken dataset, reader 2.
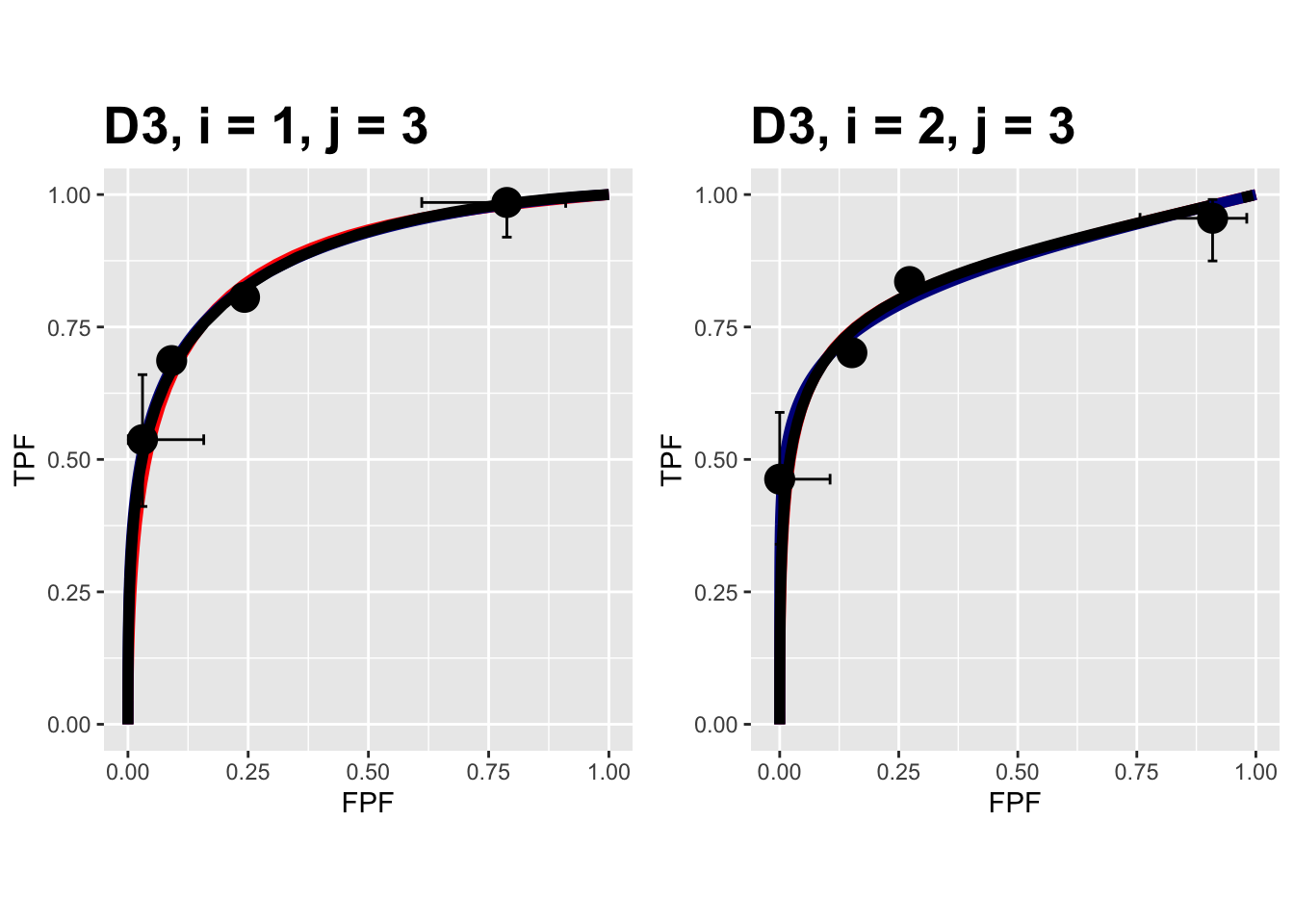
FIGURE 10.17: Composite plots in both treatments for the Franken dataset, reader 3.
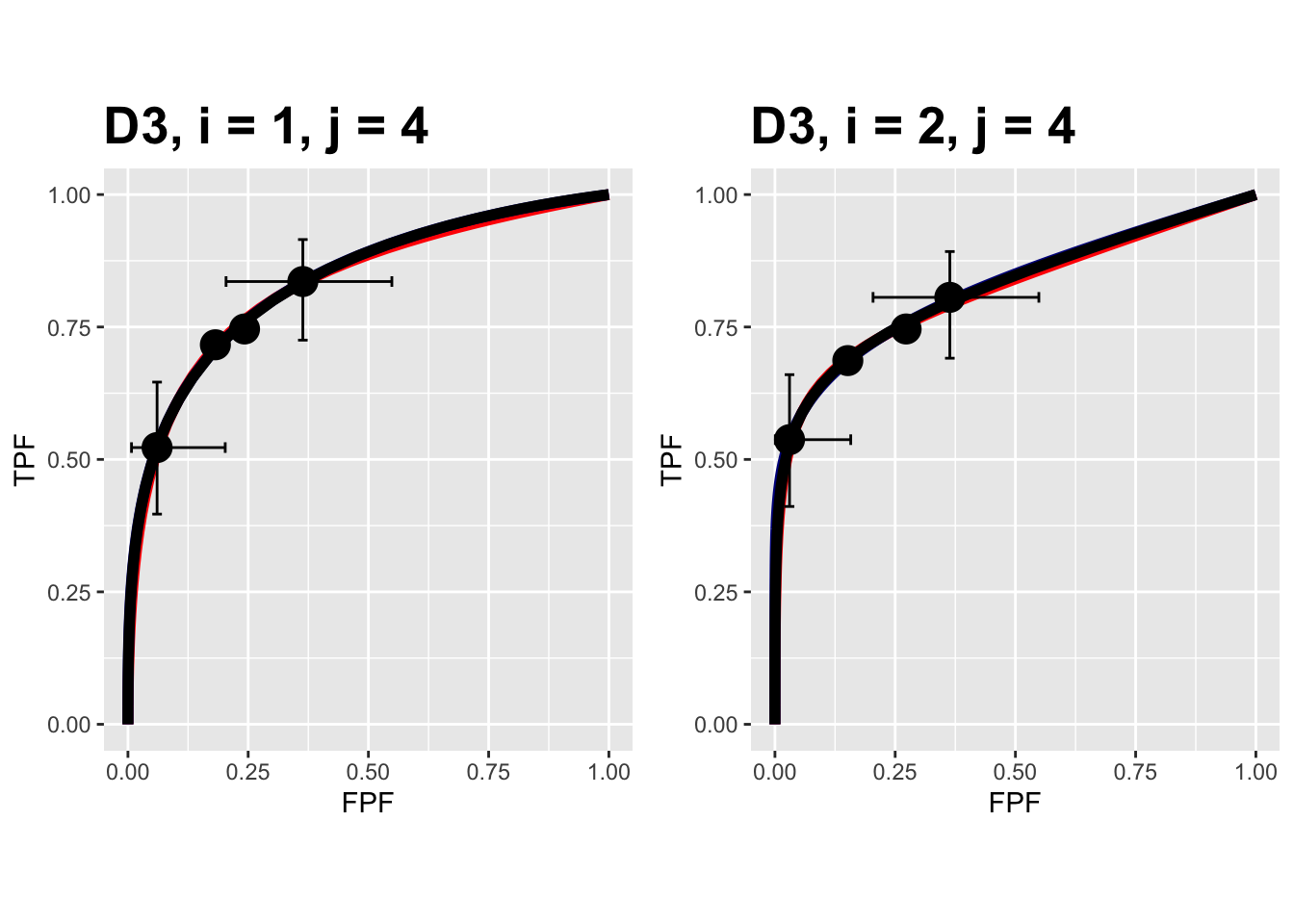
FIGURE 10.18: Composite plots in both treatments for the Franken dataset, reader 4.
REFERENCES
Comparing the RSM to the binormal model would be inappropriate, as the latter does not predict proper ROCs.↩︎
Sept. 04, 2014; the version used in this chapter is no longer distributed.↩︎
The initial value is calculated using initial estimates of parameters and the final value is that resulting from the log-likelihood maximization procedure. Since in fact negative log-likelihood is being minimized, the final value is smaller than the initial value.↩︎
In accordance with R-package policies white-spaces in the original
PROPROCoutput file names have been removed.↩︎The
VD.lrcfile in this directory is the Van Dyke data formatted for input to OR DBM-MRMC 2.5.↩︎